
لماذا تبيعك وكالة الذكاء الاصطناعي في الخليج روبوت دردشة (وما تحتاجه فعلياً)
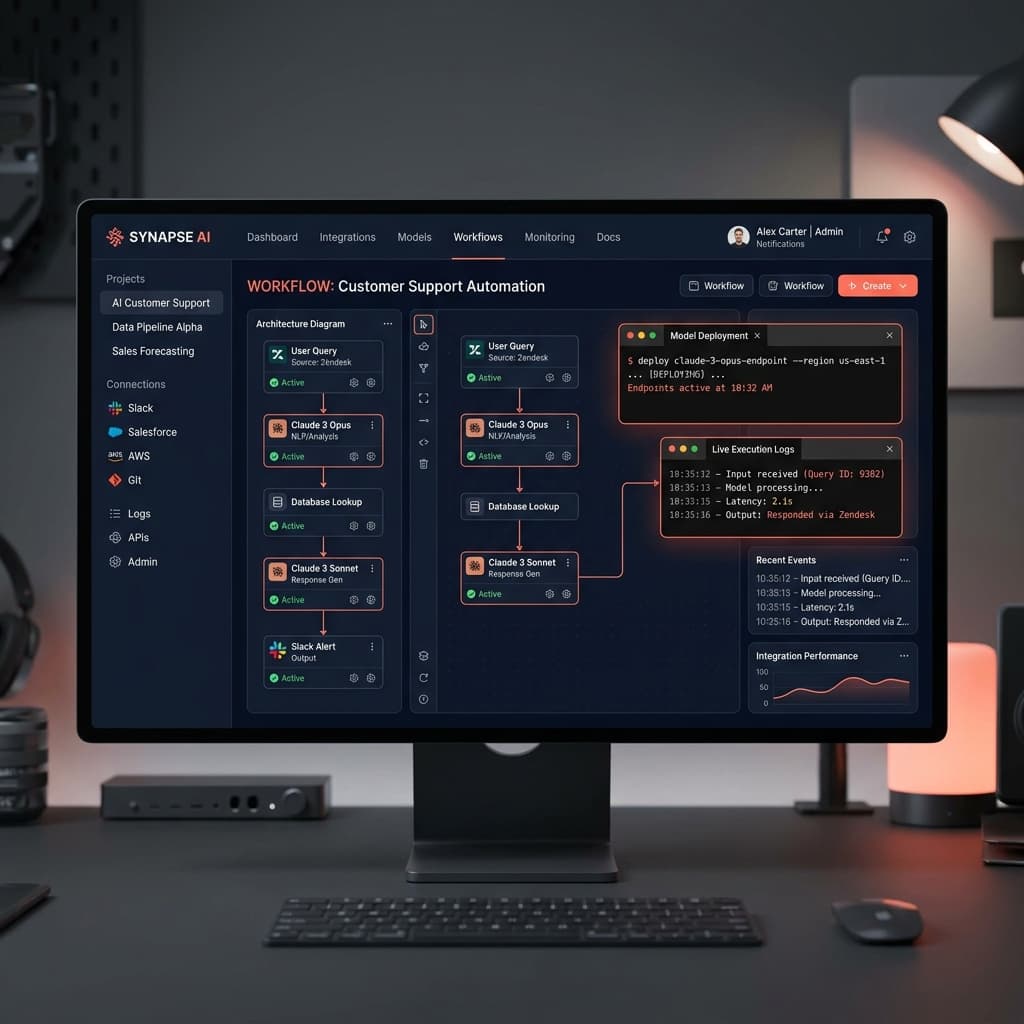
تهدر معظم الشركات في الإمارات والسعودية ميزانيات هندسية ضخمة على أدوات إثبات مفهوم للذكاء الاصطناعي (PoC) لا تصل أبداً إلى مرحلة الإنتاج. أنت لا تحتاج إلى غلاف آخر (wrapper) لـ OpenAI؛ أنت بحاجة إلى أنظمة مرنة ومتوافقة.
عند تقييم وكالة ذكاء اصطناعي مؤسسية في الخليج، يجب أن يتحول التركيز من النماذج التأسيسية (foundation models) الأساسية إلى حقائق الأمان الصارم، والهندسة المعمارية، وظروف النشر. تتحرك المنطقة بسرعة ولديها ميزانيات ضخمة لتنفيذ تطبيقات على نطاق واسع.
ومع ذلك، يشعر قادة الشركات بإحباط متزايد من الموردين الذين يقدمون وعوداً مبالغاً فيها ولا يفون بها. إذا كانت مؤسستك تتطلع إلى دمج الذكاء الاصطناعي، فأنت بحاجة إلى شركة تبني بنية تحتية برمجية قوية، وليس مجرد عروض تقديمية.
وهم روبوت الدردشة (Chatbot) ولماذا يفشل
السوق حالياً غارق بالموردين الذين يصورون البرامج النصية الأساسية (basic scripts) على أنها هندسة معقدة. تبيعك معظم الوكالات روبوت دردشة وتسميه ذكاءً اصطناعياً.
يقومون بربط واجهة برمجة تطبيقات (API) لنموذج لغوي قياسي (LLM) بموقعك العام أو موسوعة الويكي الداخلية لديك، ويكتبون توجيهاً أساسياً للنظام (system prompt)، ويعتبرون المشروع منتهياً. هذا النهج يفشل فوراً داخل بيئة مؤسسية حقيقية.
لا يمكن لبرنامج نصي أساسي للتوليد المعزز بالاسترجاع (RAG) التعامل مع أذونات مستوى المستندات (document-level permissions). في التسلسل الهرمي للشركة، إذا طرح رئيسك التنفيذي سؤالاً، يجب أن يصل إلى بيانات مختلفة عن تلك التي يصل إليها المتدرب الذي يستعلم في نفس النظام.
عندما تقوم بنشر روبوت دردشة أساسي دون تحكم صارم في الوصول القائم على الدور (RBAC)، فإنك تتسبب في مخاطر هائلة لتسرب البيانات. سيقضي فريقك الهندسي الأشهر الستة المقبلة في تصحيح ثغرات حقن التوجيه (prompt injection vulnerabilities) بدلاً من بناء الميزات الأساسية للمنتج.
تقييم وكالة ذكاء اصطناعي مؤسسية في الخليج: الألعاب مقابل البنية التحتية
نستخدم في Seven Labs نموذجاً عقلياً بسيطاً: هل تشتري لعبة، أم تبني بنية تحتية؟
تعمل الألعاب بشكل مثالي في العروض التوضيحية المنضبطة والمعزولة (isolated demos). تبدو رائعة في العروض التقديمية لمجالس الإدارة. بينما تتعامل البنية التحتية مع الحالات النادرة (edge cases)، وحدود الـ API، وخطوط أنابيب البيانات غير المهيكلة، ومتطلبات الامتثال الصارمة.
تتطلب البنية المعمارية بمستوى الإنتاج خطوط أنابيب تقييم صارمة (evaluation pipelines). إذا قمت بتعديل توجيه النظام أو تحديث نموذج التضمين، فإنك تحتاج إلى اختبار انحدار آلي (automated regression testing) لإثبات أن الدقة لم تنخفض عبر آلاف حالات الاختبار.
تحتاج أيضاً إلى مزامنة قاعدة البيانات الموجهة (vector database) لتحديثها في الوقت الفعلي عندما تتغير المستندات المصدرية الأساسية. البيانات القديمة (Stale data) في قاعدة البيانات الموجهة تؤدي مباشرة إلى هلاوس مؤسسية (corporate hallucinations).
هذا هو الفرق الدقيق بين الوكالة التي تكتب استدعاءات API والشركة الهندسية التي تشحن AI platforms مرنة. نحن نبني أنظمة مع إمكانية المراقبة (observability) مدمجة من اليوم الأول.
عند حدوث شذوذ (anomaly)، تحتاج إلى معرفة السبب الدقيق الذي جعل النموذج يعطي إجابة محددة. يجب أن تكون قادراً على تتبع مسار التنفيذ وتصحيح الجزء الدقيق (document chunk) من المستند الذي اعتمد عليه.
إذا كنت في هذه المرحلة، فهنا عادة ما توفر مكالمة تحديد النطاق معنا 3-4 أشهر من وقت الهندسة الضائع.
الأمان، وإقامة البيانات، وواقع الفجوة الهوائية
تعمل شركات الخليج، خاصة في القطاعين المالي والحكومي، في ظل أطر تنظيمية صارمة. سيادة البيانات (Data sovereignty) ليست خياراً.
لا يمكنك إرسال سجلات مالية غير منقحة أو بيانات شخصية (PII) إلى نقطة نهاية API عامة مستضافة في مركز بيانات أمريكي. ستقوم فرق الامتثال والشؤون القانونية لديك بمنع النشر بشكل صحيح في اليوم الأول.
لقد قمنا مؤخراً بهندسة حل معزول (air-gapped) لبنك إقليمي. خلال مرحلة هندسة البنية، قمنا بتخطيط متطلبات انعدام الثقة (zero-trust requirements) المطلقة الخاصة بهم.
قمنا بنشر نماذج مفتوحة المصدر مضبوطة بدقة (fine-tuned) مباشرة داخل سحابتهم الافتراضية الخاصة (VPC). لم تغادر أي بيانات حساسة محيطهم أبداً. تمت جميع عمليات تقطيع المستندات، والتضمين، والاستدلال (inference) محلياً.
لم نكتفِ بنشر النموذج فحسب؛ بل أثبتنا أمانه. نفذ فريقنا اختبارات فريق أحمر (red-teaming) صارمة ضد البنية التحتية. يمكنك مراجعة المنهجية في دراسة حالة اختبار اختراق البنك VAPT.
إن نظام الذكاء الاصطناعي الذي لا يستطيع اجتياز اختبار اختراق صارم هو عبء مؤسسي هائل، وليس أصلاً تكنولوجياً.
الهندسة للغة العربية والسياقات المحلية المعقدة
تميل معظم أدوات الذكاء الاصطناعي الجاهزة بشدة نحو بناء الجملة الإنجليزية والنصوص الرقمية النظيفة. وتتعطل عندما تُقدم إلى الواقع التشغيلي لشركات الخليج.
من المحتمل أن تحتوي أنظمتك على مزيج من المستندات العربية والإنجليزية، وملفات PDF حكومية ممسوحة ضوئياً وبها علامات مائية، وجداول مالية معقدة. لا يمكن لخط أنابيب OCR القياسي تحليل هذه الملفات بشكل صحيح.
إذا لم يستطع النموذج قراءة الجدول بشكل صحيح أثناء مرحلة الإدخال (ingestion phase)، فلن تتمكن أي هندسة توجيه (prompt engineering) من إصلاح المخرجات. تظل قاعدة "قمامة تدخل، قمامة تخرج" (Garbage in, garbage out) هي القانون الأساسي للذكاء الاصطناعي.
نحن نبني خطوط أنابيب إدخال مخصصة تتعامل مع الوثائق ثنائية اللغة بشكل صحيح. نستخدم استراتيجيات تقطيع متقدمة تحترم الحدود الدلالية (semantic boundaries) في كل من اللغتين العربية والإنجليزية.
وهذا يضمن أن البحث الموجه (vector search) يسترجع السياق الدقيق المطلوب، بدلاً من سحب جمل مجزأة لا معنى لها من ملف PDF تم تحليله بشكل سيئ.
واقع التقيد بالمورد مع أغلفة SaaS للذكاء الاصطناعي
تقع العديد من الشركات في فخ شراء منصات SaaS ثقيلة تعمل كأغلفة (wrappers) حول نماذج اللغة الكبيرة القياسية.
تعد هذه المنصات بتكامل سلس ولكنها سرعان ما تصبح عبئاً هائلاً. أنت مقيد بنظامهم البيئي المحدد، ونماذج التسعير الخاصة بهم، ودورات التحديث (update cycles) الخاصة بهم.
إذا تم إصدار نموذج مفتوح المصدر في الشهر المقبل أرخص بنسبة 50% وأكثر دقة بنسبة 20% لحالة الاستخدام الخاصة بك، فلن تتمكن من الانتقال إليه بسهولة. أنت مرتبط بخريطة طريق המورد (vendor roadmap).
نحن نبني معماريات الذكاء الاصطناعي استناداً إلى مبادئ تركيبية ومفتوحة المصدر (modular, open-source principles). نقوم بفصل طبقة التخزين (مثل Postgres مع pgvector) عن طبقة التنسيق (orchestration layer) ومحرك الاستدلال.
تمنحك هذه التركيبية الحرية في استبدال النماذج الأساسية مع تطور التكنولوجيا. أنت تمتلك البنية التحتية، ولن يتم احتجازك كرهينة لتغييرات الـ API الخاصة بمورد واحد أبداً.
فخ "البناء مقابل الشراء" للفرق الداخلية
سيقول مهندسوك الداخليون إنه يمكنهم بناء هذا. وسيشيرون إلى أن المكتبات مفتوحة المصدر متاحة والوثائق واضحة.
هذه هي المحادثة الخاطئة. بناء نموذج أولي لتطبيق ذكاء اصطناعي في عطلة نهاية أسبوع هو أمر تافه. صيانته في بيئة الإنتاج على مدار 18 شهراً هي تخصص هندسي مختلف تماماً.
واجهات الـ APIs تصبح قديمة (deprecate) بسرعة. يصبح التعامل مع نافذة السياق (context window) معقداً بشكل كبير. دقة البحث الدلالي تتدهور عندما تنمو قاعدة بياناتك من مئات المستندات إلى ملايين.
إن توظيف مهندسي ذكاء اصطناعي مخصصين في دبي للحفاظ على هذه البنية التحتية هو أمر مكلف للغاية. علاوة على ذلك، فإن مجموعة المهندسين الذين قاموا فعلياً بشحن أنظمة ذكاء اصطناعي للإنتاج هي صغيرة جداً.
عندما يتولى فريق هندستك الأساسي هذا الأمر، فإن سرعة دورات التطوير (sprint velocity) لميزات المنتج الأساسية الحقيقية تنخفض إلى الصفر. أنت تتبادل فعلياً تطوير المنتج (product iteration) بصيانة الذكاء الاصطناعي.
الشراكة مع استوديو يركز على الهندسة تزيل هذا العبء تماماً. يتيح ذلك لفريقك الداخلي التركيز كلياً على منطق الأعمال الخاص (proprietary business logic) بينما ندير نحن انحراف البنية التحتية للذكاء الاصطناعي (AI infrastructure drift).
التكاليف الخفية لبنية الذكاء الاصطناعي الضعيفة
عندما تشتري حلاً سطحياً، فإنك تدفع ثمنه مرتين. الفاتورة الأولية من الوكالة هي مجرد البداية.
تظهر التكاليف الخفية عندما تحاول التوسع (scale). ستؤدي استعلامات البحث الموجه غير المحسنة إلى خنق قاعدة بياناتك. وستتسبب استدعاءات الـ API غير المخزنة مؤقتاً (uncached) في خروج تكاليف الاستدلال الشهرية عن السيطرة.
ستدفع أيضاً ثمن زمن الانتقال (latency). قد يستغرق خط أنابيب الذكاء الاصطناعي غير المحسن عشر ثوانٍ لإرجاع استعلام. في بيئة الإنتاج التي تواجه مستخدمين حقيقيين، يدمر زمن الانتقال العالي معدلات التبني.
يتطلب إصلاح هذه العيوب المعمارية اقتلاع الأساس. ينتهي بك الأمر بالدفع لشركة هندسية حقيقية لإعادة كتابة النظام بأكمله من الصفر. نحن نستخدم التخزين المؤقت الدلالي (semantic caching) وعمليات النشر الطرفية (edge deployments) لضمان استجابة أنظمتك في أجزاء من الألف من الثانية، وليس ثوانٍ.
الأسئلة الثلاثة التي يجب أن تطرحها على شريك الذكاء الاصطناعي القادم
توقف عن سؤال الموردين عن النماذج التأسيسية التي يستخدمونها. النماذج نفسها هي سلع تتغير كل ثلاثة أشهر. ابدأ بسؤالهم عن كيفية تصميمهم المعماري للنظام حول النموذج.
أولاً، اسأل كيف يتعاملون مع تعيين أذونات المستندات (document permission mapping) أثناء البحث الموجه. إذا ترددوا أو اقترحوا حلاً بديلاً، فهم لم يبنوا أبداً أنظمة RAG مؤسسية.
ثانياً، اطلب منهجيتهم الدقيقة لاختبار حقن التوجيه (prompt injection) وتسريب البيانات التلقائي (automated data exfiltration). إذا كانت إجابتهم "نحن نستخدم توجيه نظام قوياً"، فانسحب فوراً.
ثالثاً، اطلب مساراً واضحاً للنشر المحلي (local deployment). حتى لو بدأت العمل على بنية تحتية سحابية مدارة اليوم، فإن التغييرات التنظيمية في الإمارات قد تجبرك على النشر الداخلي (on-premise) غداً. يجب أن تدعم البنية التحتية الخاصة بك هذا المحور دون إعادة كتابة كاملة.
لقد انتهت دورة الضجيج الأولية. تدرك الشركات أن دمج الذكاء الاصطناعي يتطلب هندسة برمجيات صارمة، وبروتوكولات أمان صارمة، ومعرفة معمارية عميقة. لا ترضَ بلعبة أخرى.
إذا كنت تقيم شركاء الذكاء الاصطناعي في الإمارات أو باكستان، احجز مكالمة تحديد نطاق مدتها 30 دقيقة مع Seven Labs: https://calendly.com/seven-labs-intro