
كيف نحدد نطاق مشاريع الذكاء الاصطناعي التي لا تنفجر في بيئة الإنتاج
تفشل معظم مبادرات الذكاء الاصطناعي في الشركات لأن فرق الهندسة تعامل نماذج اللغة الكبيرة (LLMs) وكأنها واجهات برمجة تطبيقات حتمية (deterministic REST APIs). عند تحديد نطاق مشاريع الذكاء الاصطناعي، فإن الفشل في أخذ المخرجات الاحتمالية والحالات النادرة (edge cases) في الاعتبار يضمن حدوث انهيار في بيئة الإنتاج (production) بمجرد زيادة حجم المستخدمين.
إذا كان فريقك الداخلي يعتقد أنه يمكنه تغليف نقطة نهاية لـ OpenAI (endpoint) في إطار FastAPI ويسمي ذلك نظاماً مؤسسياً، فأنت تسير بخطى ثابتة نحو كارثة.
فخ "يمكننا بناء هذا داخلياً"
يسمع مديرو التكنولوجيا (CTOs) باستمرار نفس الاقتراح من فرق الهندسة الخاصة بهم: "نحتاج فقط إلى مفتاح API، وLangChain، وقاعدة بيانات موجهة (vector database). يمكننا شحن هذا في دورة تطوير (sprint) واحدة."
يبدو الأمر بسيطاً. يستغرق بناء النموذج الأولي (prototype) ثلاثة أيام. ويبدو العرض التوضيحي (demo) خالياً من العيوب أمام الفريق التنفيذي.
لكن العرض التوضيحي ليس نظاماً. ما يقترحه مهندسوك في الواقع هو تحمل عبء صيانة ضخم ومفتوح ليسوا مستعدين للتعامل معه.
تعتمد هندسة البرمجيات القياسية على حالة حتمية (deterministic state). تُمرر مدخلاً، وتحصل على مخرج متوقع. يدخل الذكاء الاصطناعي الاحتمالية إلى منطق تطبيقك الأساسي.
مطوروك لبرمجة الويب ومهندسو الواجهة الخلفية (backend engineers) ليسوا خبراء في عمليات تعلم الآلة (MLOps). إنهم لا يعرفون كيفية التعامل مع إخفاقات الاسترجاع الصامتة (silent retrieval failures)، أو تدهور نافذة السياق، أو التراجعات الحتمية في حدود الرموز (token limit regressions) التي تحدث تحت ضغط الاستخدام.
تكلفة الفرصة البديلة (opportunity cost) الناتجة عن تكليف فريق منتجك الأساسي ببناء بنية تحتية مخصصة للذكاء الاصطناعي هي تكلفة هائلة. أنت تحرق سرعة مهام التطوير (sprint velocity) في حل مشكلة تم حلها بالفعل بواسطة شركات هندسية متخصصة.
بعد ثمانية عشر شهراً، يغرق فريقك الداخلي في صيانة الأغلفة المخصصة (custom wrappers)، ومحاربة التقيد بالمورد (vendor lock-in)، وإعادة كتابة المنطق الأساسي في كل مرة يهمل فيها مزود النموذج واجهة برمجة تطبيقات (API). أنت تخسر وقت الوصول إلى السوق (time to market)، وتتضخم تكاليف الصيانة بشكل خيالي.
تحديد نطاق مشاريع الذكاء الاصطناعي: الانتقال من العروض التوضيحية إلى الحتمية
الجزء الأصعب في تحديد نطاق مشاريع الذكاء الاصطناعي هو تحديد ما يحدث عندما يفشل النموذج حتمياً.
يسأل تحديد النطاق في البرمجيات القياسية: "ما الذي يجب أن يفعله النظام؟" بينما يجب أن يسأل تحديد النطاق في الذكاء الاصطناعي المؤسسي: "كيف يتراجع النظام بسلاسة (gracefully degrade) عندما يهلوس (hallucinates) الـ LLM، أو يُسقط السياق، أو يواجه مدخلات خارج التوزيع (out-of-distribution inputs)؟"
الحالات النادرة غير المتوقعة (Unforeseen edge cases) وفشل التوسع الناتج عن تحديد نطاق سيء سيشلان عملية النشر. تميل الفرق بطبيعتها إلى التحسين من أجل "المسار السعيد" (happy path) حيث يكون استعلام المستخدم منظماً بشكل مثالي واسترجاع المتجهات خالياً من العيوب.
في الإنتاج (production)، لا يتبع المستخدمون المسار السعيد. يكتبون استعلامات غامضة وسيئة التنسيق. يقومون بلصق ملفات PDF بحجم 50,000 رمز تُرهق نافذة السياق وتتسبب في إسقاط النموذج للتعليمات بصمت.
يحاول المستخدمون حقن التوجيه (prompt injection). ويصلون إلى حدود المعدل (rate limits). ويطلبون بيانات ليس لديهم صلاحية لرؤيتها.
إذا لم يحدد النطاق الأولي لمشروعك بشكل صريح خطوط أنابيب التقييم (evaluation pipelines)، والأساليب البديلة للتراجع (fallback heuristics)، وحواجز الأمان الآلية، فسوف ينفجر نظامك في الإنتاج.
يُملي تحديد النطاق بمستوى الإنتاج (production-grade scope) بالضبط كيف يتم التقاط مخرجات JSON المشوهة (malformed) من الـ LLM وإعادة محاولتها قبل أن تكسر تطبيقاتك اللاحقة. ويحدد اتفاقيات مستوى خدمة زمن الانتقال (latency SLAs) واستراتيجيات التخزين المؤقت المطلوبة للوفاء بها.
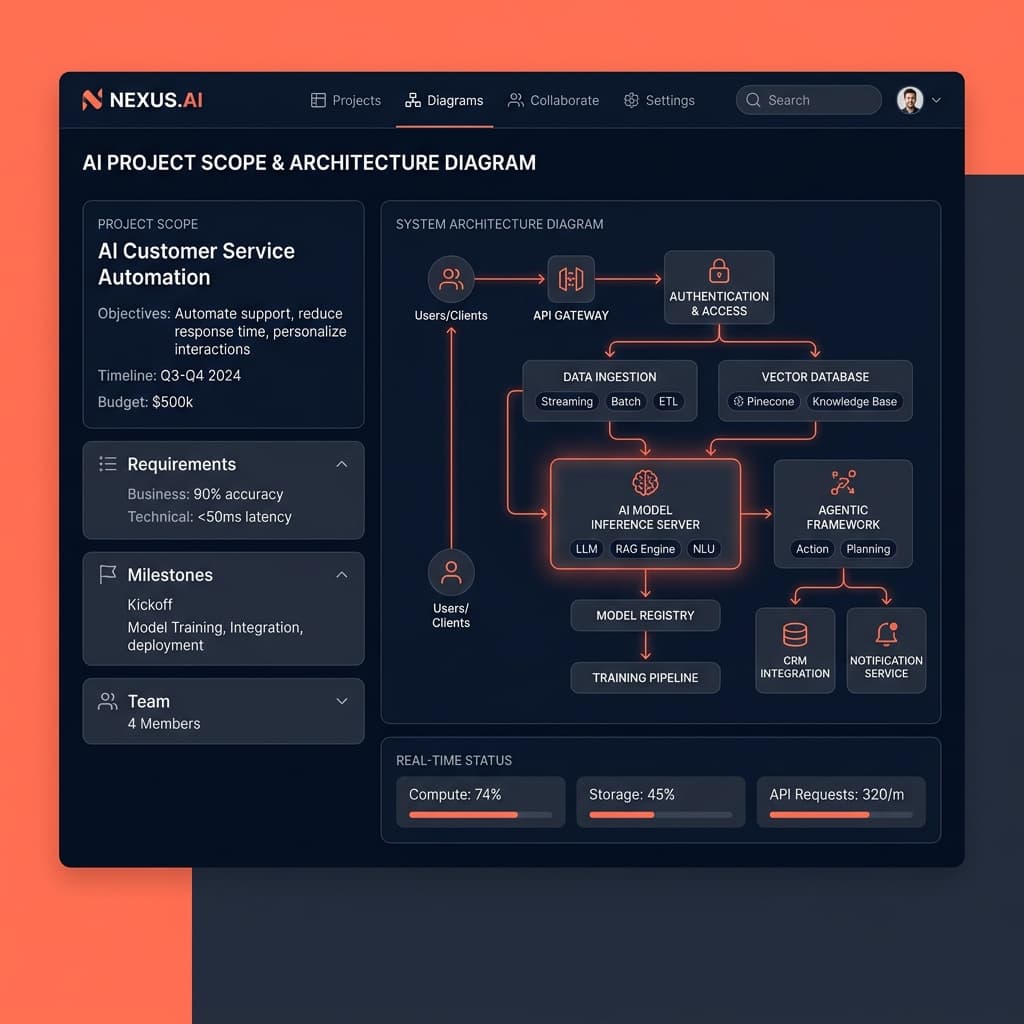
إطار العمل: الهندسة المعمارية تتفوق على هندسة التوجيهات (Prompt Engineering)
عندما نحدد نطاق ارتباطاتنا في Seven Labs، فإننا نجبر القيادة الفنية على تغيير نموذجها العقلي. توقف عن التفكير في التوجيه (prompt). وابدأ التفكير في خط الأنابيب (pipeline).
إطار العمل الذي نستخدمه هو قاعدة 85/15 في معمارية الذكاء الاصطناعي. بالضبط 85% من جهدك الهندسي يجب أن يُنفق على تنسيق البيانات (data orchestration)، وإدارة الحالة، ومنطق الاسترجاع، والتقييم.
15% فقط تخص تفاعل الـ LLM نفسه.
تتطلب البنية المعمارية القوية تخزيناً مؤقتاً دلالياً (semantic caching) لتقليل زمن الانتقال وتكاليف واجهة برمجة التطبيقات (API). وتتطلب إعادة كتابة الاستعلام (query rewriting) - وهي خطوة وسيطة حيث يتم تطبيع (normalized) مدخلات المستخدم الخام قبل أن تصل إلى قاعدة البيانات الموجهة.
كما تتطلب طبقة بنية تحتية مخصصة لتنقيح بيانات تحديد الهوية الشخصية (PII redaction). وتتطلب معماريات بحث هجينة تجمع بين تضمينات المتجهات الكثيفة (dense vector embeddings) والبحث بالكلمات الرئيسية BM25، لأن التشابه المتجهي وحده سيء للغاية في العثور على أرقام تسلسلية دقيقة أو اختصارات.
لا يمكن حل أي من تحديات البنية التحتية هذه بكتابة توجيه (prompt) أفضل.
إذا كانت وثيقة تحديد النطاق الخاصة بك تقضي صفحات أكثر في مناقشة اختيار النموذج بين GPT-4 و Claude بدلاً من تحديد البنية التحتية للبيانات الخاصة بك، فأنت تقوم بتحسين المتغير الخطأ.
إذا كان فريقك الهندسي الداخلي يكافح لنقل ميزة الذكاء الاصطناعي من نموذج أولي إلى الإنتاج، فهنا عادة ما توفر مكالمة تحديد النطاق معنا 3-4 أشهر من وقت الهندسة الضائع.
النجاة من القيود الأمنية الصارمة
تصبح إخفاقات تحديد النطاق كارثية عندما تعمل في صناعات خاضعة للرقابة مثل البنوك، أو التكنولوجيا المالية، أو الرعاية الصحية. لا يمكنك إقحام الأمان في خط أنابيب ذكاء اصطناعي بعد بنائه (retrofit security).
عندما قمنا ببناء نظام تحليل ثغرات آلي لمؤسسة مالية كبرى (اقرأ دراسة حالة بنك VAPT)، كان النطاق مقيداً تماماً بمتطلبات انعدام الثقة (zero-trust constraints) الصارمة.
لم نكن نستطيع ببساطة إرسال سجلات اختبار الاختراق وبيانات هيكل الشبكة (network topology) إلى واجهة برمجة تطبيقات (API) سحابية عامة. تطلب النطاق نشر نموذج معزول (air-gapped) محلياً على بنية تحتية سيادية.
لقد صممنا خط أنابيب يستخدم نماذج مفتوحة الأوزان (open-weight models) منتشرة على خوادم معدنية (bare metal). وقمنا بتنفيذ عزل للمستأجرين على مستوى الطلب (request-level tenant isolation) وتحكم صارم في الوصول القائم على الدور (RBAC) في طبقة التضمين (embedding layer).
ضمن ذلك أن التلوث المتبادل بين مجموعات بيانات الأقسام المختلفة مستحيل التشفير (cryptographically impossible).
إذا كان النطاق الأولي قد افترض إمكانية الوصول إلى Cloud API، لكان فريق أمن المعلومات (InfoSec) في البنك قد رفض البنية المعمارية بأكملها خلال مراجعة النشر الأولى.
التنبؤ بمتطلبات الامتثال، وإقامة البيانات (data residency)، ومتطلبات SOC 2 في اليوم الأول هو الطريقة الوحيدة لشحن الذكاء الاصطناعي المؤسسي في أسواق الخليج والأسواق العالمية. يعني تحديد النطاق للأمان تخطيط حدود تدفق البيانات الدقيقة قبل كتابة سطر واحد من التعليمات البرمجية.
تحديد عبء الصيانة في "اليوم الثاني"
شحن المشروع إلى الإنتاج هو "اليوم الأول" (Day 1). أما "اليوم الثاني" (Day 2) فهو حيث تدمر التكاليف الخفية لسوء تحديد النطاق ميزانيتك التشغيلية.
يتم تحديث نماذج LLMs باستمرار خلف الكواليس. النظام الذي يعمل بشكل لا تشوبه شائبة اليوم سيتدهور بصمت عندما يغير الـ API الأساسي ضبط المحاذاة (alignment tuning) أو مرشحات الأمان.
سيتعرض فهرس قاعدة البيانات الموجهة (vector database index) الخاصة بك للانحراف (drift) مع تطور مجموعة المستندات الأساسية (document corpus) الخاصة بك. ستنخفض جودة الاسترجاع لديك ببطء، وسيبدأ المستخدمون في الشكوى من أن الذكاء الاصطناعي أصبح "أغبى".
من في فريقك يراقب ذلك؟ من يقوم بتشغيل اختبارات الانحدار (regression tests) ضد مجموعة بيانات ذهبية في كل مرة يتم فيها تحديث إصدار النموذج؟
عندما ننشر AI platforms لعملائنا من الشركات، فإننا نحدد نطاق خط أنابيب CI/CD للنماذج نفسها. هذا يُعرف بـ LLMOps، وهو مطلب أساسي للإنتاج.
نحن ننشر أدوات قياس عن بعد (telemetry) تتتبع زمن انتقال الرموز (token latency)، ومعدلات الهلوسة، والتكلفة لكل استعلام في الوقت الفعلي. نبني حلقات تقييم آلية باستخدام أطر عمل تعتبر الـ LLM كقاضٍ (LLM-as-a-judge) لالتقاط التراجعات (regressions) قبل أن يراها المستخدمون.
بدون هذه البنية التحتية في نطاق مشروعك، ليس لديك منتج ذكاء اصطناعي. بل لديك عبء قانوني (liability) غير خاضع للمراقبة وينتظر الانكسار.
توقف عن بناء الألعاب
يعد تحديد نطاق مشروع ذكاء اصطناعي ممارسة أساسية للتخفيف من المخاطر. فإما أن تقوم بالهندسة من أجل قابلية التوسع، والأمان، والحتمية (determinism) منذ البداية، أو ستدفع ثمن إعادة الكتابة الشاملة بعد ستة أشهر.
لا تدع فريقك الهندسي يبني لعبة عندما تحتاج مؤسستك إلى نظام آمن وعالي التوافر.
إذا كنت تقيم شركاء الذكاء الاصطناعي في الإمارات أو باكستان لبناء بنية تحتية بمستوى الإنتاج، احجز مكالمة تحديد نطاق مدتها 30 دقيقة مع Seven Labs: https://calendly.com/seven-labs-intro