
AI Deployment in Air-Gapped Financial Networks: Ein praktischer Architektur-Leitfaden
Finanz-Engineering-Teams stehen vor einer strikten binären Wahl: Compliance und Fraud Detection mit Large Language Models modernisieren oder die Data Residency aufrechterhalten, indem Netzwerke vollständig isoliert bleiben. Sie können sensible Kunden-PII nicht einfach an eine externe API weiterleiten, ohne sofortige Compliance Breach-Risiken auszulösen. Zentralbank-Mandate am Golf und globale SOC 2-Anforderungen verbieten diese Art von Data Leakage ausdrücklich.
Um dies zu lösen, müssen Infrastructure Teams das AI Deployment in Air-Gapped Networks beherrschen. Dies erfordert das Kappen aller externen Abhängigkeiten und die Architektur von Systemen, die ohne jegliche externe Netzwerkverbindung arbeiten. Es ist ein grundlegender Wandel vom Cloud-Native Engineering.
Das Compliance Breach Risiko der "Guten Absichten"
Ihre internen Entwickler werden Ihnen sagen, dass sie an einem Wochenende eine Offline Retrieval-Augmented Generation (RAG) Pipeline bauen können. Sie beantworten die falsche Frage. Ein Open-Source-Modell lokal auf einem Laptop zum Laufen zu bringen, ist trivial.
Dieses Modell für die Production innerhalb eines eingeschränkten Finanznetzwerks abzuhärten, ist eine völlig andere Engineering-Disziplin. Der primäre Schmerzpunkt ist die Data Residency. Wenn ein Nutzer ein Modell mit Transaction Histories oder KYC-Dokumenten abfragt, dürfen diese Daten das lokale Netzwerk unter keinen Umständen verlassen.
Der Failure Mode hier ist schwerwiegend. Ein einziger Entwickler, der versehentlich sensible Daten in einem Cloud-gehosteten Observability-Tool protokolliert – oder einen versteckten Aufruf an OpenAI zum Debuggen einbettet –, kann ein massives Compliance Breach-Risiko auslösen. Strafen in regulierten Märkten berechnen sich nach einem Prozentsatz des globalen Umsatzes, nicht nach Pauschalgebühren.
Dies schafft das "Shadow AI"-Problem. Engineers, frustriert durch strenge Netzwerkbeschränkungen, finden versteckte Workarounds, um auf Cloud-Modelle zuzugreifen. Die einzige Verteidigung besteht darin, eine vollständig offlinefähige Alternative in Production-Qualität bereitzustellen, die genauso schnell und zuverlässig ist wie externe APIs.
Design von AI Deployments in Air-Gapped Networks
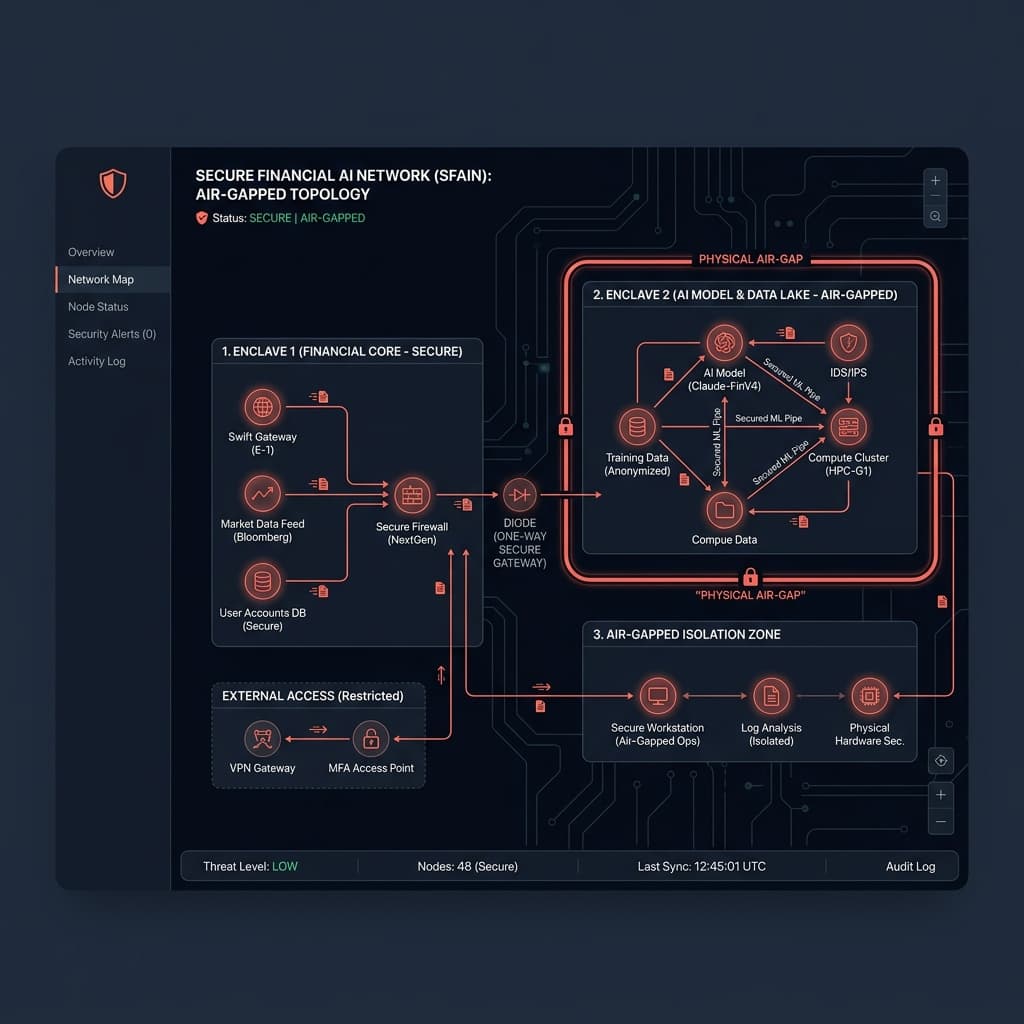
Standard Cloud-Native AI Architectures gehen von unendlicher Bandbreite und ständiger Konnektivität zu Package Registries aus. Die Entwicklung von AI Deployments in Air-Gapped Networks erfordert die Umkehrung dieses Paradigmas. Ihr System kann nicht nach außen zu Hugging Face, NPM oder externen Telemetry Services rufen.
Wir unterteilen die Offline Infrastructure in vier isolierte Tiers:
1. Die Offline Model Registry: Model Weights (safetensors) und Tokenizers müssen extern heruntergeladen, auf Supply Chain Attacks gescannt und physisch in eine interne Artifact Registry übertragen werden. Tokenizers versuchen oft, zur Laufzeit Konfigurationsdateien herunterzuladen – diese Aufrufe müssen abgefangen und in lokale Dateien umgeleitet werden.
2. Die Inference Engine: Sie können sich nicht auf Managed Endpoints verlassen. Wir implementieren optimierte lokale Inference Servers wie vLLM oder Text Generation Inference (TGI), die streng für die Offline Execution konfiguriert sind. Diese laufen auf dedizierten Bare-Metal GPU Clusters innerhalb der Corporate Firewall.
3. Der Local Vector Store: Für RAG-Implementierungen müssen Vector Databases wie Qdrant oder Milvus lokal bereitgestellt werden. Wir befreien diese Container vor dem Deployment von jeglichen standardmäßigen Telemetry- oder "Phone Home"-Analytics-Konfigurationen.
4. Air-Gapped Telemetry: Observability kann nicht an Datadog oder New Relic ausgelagert werden. Wir implementieren interne Prometheus und Grafana Stacks, um GPU Utilization, Token Generation Latency und Memory Spikes zu überwachen.
Das "U-Boot"-Mentalmodell für Offline AI
Wenn Sie eine Offline Infrastructure bewerten, stellen Sie sich Ihre AI Application wie ein U-Boot vor. Einmal deployt, ist es komplett autonom. Es kann nicht nach externer Hilfe rufen, sich selbst patchen oder im laufenden Betrieb neue Karten herunterladen.
Dieses Framework zwingt Engineering- und Security-Teams dazu, sich abzustimmen. Wenn das System ein Update benötigt – sei es ein neues Llama 3 Model Weight oder ein Security Patch für den Inference Server –, erfordert es ein "Andocken".
In einem Enterprise Setting bedeutet Andocken die Nutzung sicherer Data Diodes oder streng kontrollierter DMZ Jump Hosts. Updates werden als unveränderliche Artifact Bundles behandelt. Sie werden Static Analysis, Malware Scanning und Artifact Signing unterzogen, bevor sie den Air Gap überqueren.
Wenn Ihr Team davon ausgeht, dass es während des Production Deployments einfach einen Package Manager Command ausführen kann, um eine fehlende Dependency zu installieren, wird Ihre Architektur scheitern.
Wenn Sie an diesem Punkt sind, ist dies der Punkt, an dem ein Scoping-Anruf bei uns in der Regel 3-4 Monate verschwendete Engineering-Zeit spart.
Real-World Architecture: Absicherung einer regionalen Bank
Wir haben kürzlich ein vollständig offlinefähiges AI System für eine große Finanzinstitution entworfen. Der Auftrag war kompromisslos: hochsensible interne Compliance-Dokumente ohne externe Network Calls verarbeiten.
Der Kunde hatte zuvor einen internen Aufbau versucht. Dieser kam zum Erliegen, weil die Entwickler Dependency Conflicts ohne Internetzugang nicht auflösen konnten, was zu massiven Projektverzögerungen und gesprengten Budgets führte.
Wir implementierten lokalisierte Instanzen von optimierten, Instruction-Tuned Models, die auf stark eingeschränkten internen GPU Clusters liefen. Die Embedding Pipelines und Vector Retrieval Systems wurden containerisiert und von allen externen Network Polling Mechanismen befreit.
Aufgrund der strengen Data Residency-Anforderungen unterzogen wir die gesamte Infrastructure vor dem Go-Live unseren umfassenden VAPT Penetration Testing-Protokollen. Wir validierten, dass keine Prompt Injection das Modell dazu zwingen konnte, Network Requests auszuführen oder Daten zu exfiltrieren. Sie können die genauen architektonischen Einschränkungen und Leistungsergebnisse in unserer Case Study zum Einsatz bei einer regionalen Bank nachlesen.
Hardware Provisioning und Build vs. Buy Economics
Für CTOs und VPs of Engineering ist die Entscheidung, Offline AI zu deployen, letztlich eine wirtschaftliche Berechnung. Der Kauf von Enterprise AI Infrastructure Software führt oft zu Vendor Lock-In und undurchsichtigen proprietären Formaten.
Der interne Aufbau erfordert die Einstellung spezialisierter MLOps Engineers, die das Bare-Metal GPU Provisioning verstehen. Das Hardware Sizing ist der erste Flaschenhals. Sie können ein Air-Gapped Server Rack nicht automatisch skalieren, um plötzliche Nachfragespitzen zu bewältigen.
Capacity Planning muss den maximalen Bedarf an Token Generation berücksichtigen. Wir berechnen die genauen VRAM-Anforderungen basierend auf maximalen Concurrent Users, Context Window Sizes und Quantization Levels (z. B. AWQ oder GPTQ), bevor ein einziger Server bestellt wird.
Wir implementieren Continuous Batching Protocols, um die Hardware Utilization zu maximieren, ohne sich auf Cloud Elasticity zu verlassen. Ihre Engineers werden behaupten, dass sie diese Infrastructure verwalten können. Die Realität ist, dass die Wartung von Offline ML Pipelines Ihre besten Entwickler davon abhält, Core Financial Products zu bauen.
Wartung des Air-Gapped Systems über 18 Monate
Das Deployen des Modells macht nur 20 % der Lifecycle-Kosten aus. Die wahre Engineering Challenge ist die Wartung nach 18 Monaten. Air-Gapped Environments leiden unweigerlich an Dependency Drift.
Wenn eine kritische CVE für Ihre Vector Database veröffentlicht wird, können Sie nicht einfach ein automatisiertes Patch-Script über das Internet ausführen. Ihre Architektur muss ein striktes Offline Artifact Promotion berücksichtigen.
Wir implementieren automatisierte Pipelines, die notwendige Updates aus öffentlichen Registries in eine internetfähige DMZ ziehen. Dort werden sie gescannt, als signierte OCI-kompatible Container Images verpackt und über physische Medien oder strenge Cross-Domain-Lösungen über die sichere Grenze verschoben.
Dies garantiert, dass Ihre Offline Infrastructure gepatcht und sicher bleibt, ohne den Air Gap zu kompromittieren. Es erfordert eiserne Disziplin, ist aber der einzige Weg, AI in einer regulierten Umgebung zu betreiben.
Sichern Sie Ihre Financial AI Infrastructure
Der Aufbau einer Offline AI Infrastructure erfordert eine tiefe Abstimmung zwischen Security, Compliance und Systems Engineering. Lassen Sie Ihr internes Team nicht ein Air-Gapped Network wie eine Standard Cloud VPC behandeln. Die Risiken für Ihre Kundendaten sind zu hoch.
Wenn Sie AI-Partner in den VAE oder Pakistan evaluieren, buchen Sie einen 30-minütigen Scoping-Call mit Seven Labs: https://calendly.com/seven-labs-intro