
Implementación de IA en Redes Financieras Aisladas (Air-Gapped): Una Guía Práctica de Arquitectura
Los equipos de ingeniería financiera se enfrentan a un binario estricto: modernizar el cumplimiento y la detección de fraudes con Large Language Models, o mantener la residencia de datos aislando las redes por completo. No se puede simplemente enviar PII (Información de Identificación Personal) confidencial de los clientes a una API externa sin desencadenar riesgos inmediatos de incumplimiento normativo. Los mandatos de los bancos centrales en el Golfo y los requisitos globales SOC 2 prohíben explícitamente este tipo de fuga de datos.
Para resolver esto, los equipos de infraestructura deben dominar la implementación de IA en redes aisladas (air-gapped). Esto requiere cortar todas las dependencias externas y diseñar sistemas que operen con cero conectividad de red externa. Es un cambio fundamental desde la ingeniería nativa de la nube.
El Riesgo de Incumplimiento Normativo de las "Buenas Intenciones"
Sus desarrolladores internos le dirán que pueden construir una tubería offline de Generación Aumentada por Recuperación (RAG) en un fin de semana. Están respondiendo a la pregunta equivocada. Lograr que un modelo de código abierto se ejecute localmente en una computadora portátil es trivial.
Endurecer (hardening) ese modelo para producción dentro de una red financiera restringida es una disciplina de ingeniería completamente diferente. El principal punto de dolor es la residencia de datos. Cuando un usuario consulta un modelo con historiales de transacciones o documentos KYC, esos datos no pueden salir de la red local bajo ninguna circunstancia.
El modo de falla aquí es severo. Un solo desarrollador que accidentalmente registre datos confidenciales en una herramienta de observabilidad alojada en la nube (o que integre una llamada oculta a OpenAI para depuración) puede desencadenar un riesgo masivo de incumplimiento normativo. Las multas en los mercados regulados operan sobre un porcentaje de los ingresos globales, no con tarifas fijas.
Esto crea el problema de la "Shadow AI". Los ingenieros, frustrados por las estrictas restricciones de red, encuentran soluciones ocultas para acceder a modelos en la nube. La única defensa es proporcionar una alternativa de grado de producción y completamente offline que sea tan rápida y confiable como las APIs externas.
Diseño de Implementación de IA en Redes Air-Gapped
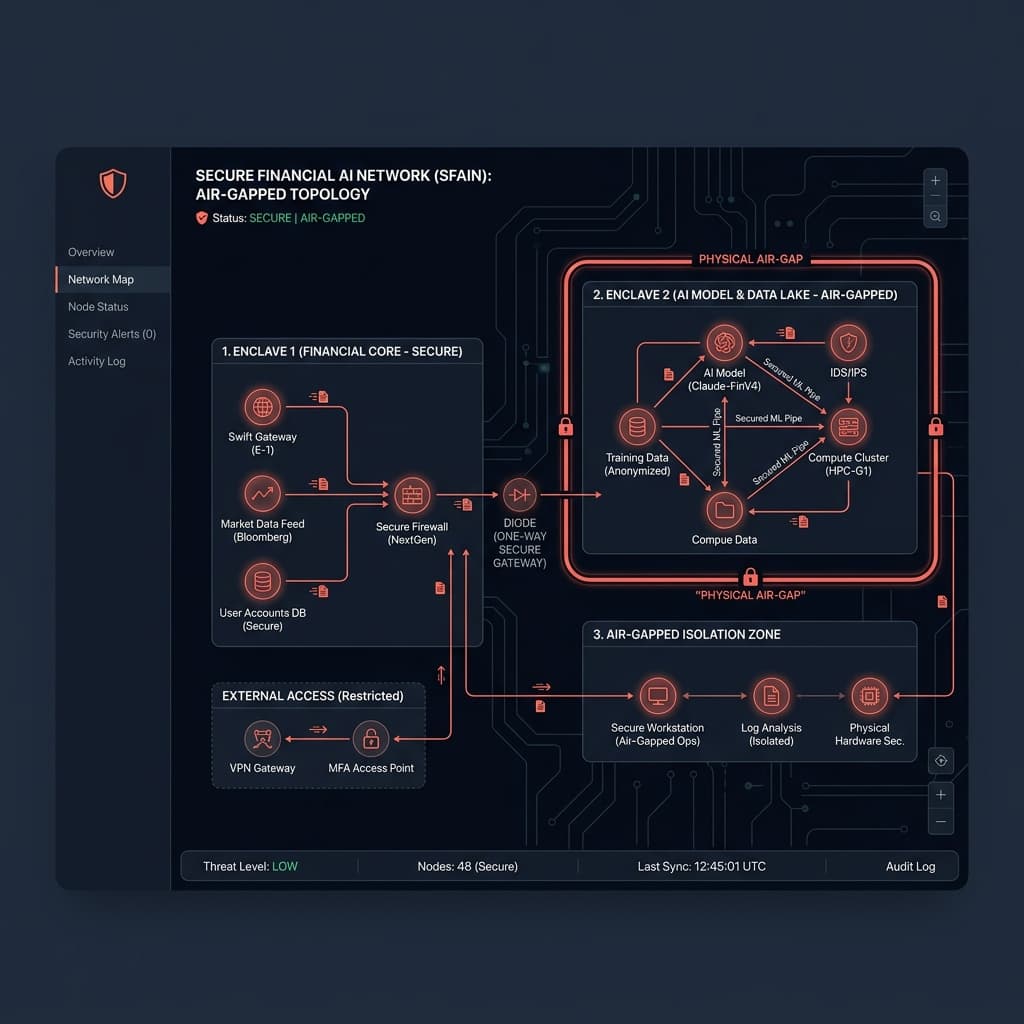
Las arquitecturas estándar de IA nativas de la nube asumen un ancho de banda infinito y una conectividad constante con los registros de paquetes. Diseñar la implementación de IA en redes air-gapped requiere invertir este paradigma. Su sistema no puede realizar llamadas a Hugging Face, NPM o servicios de telemetría externos.
Desglosamos la infraestructura offline en cuatro niveles aislados:
1. El Registro de Modelos Offline: Los pesos del modelo (safetensors) y los tokenizadores deben descargarse externamente, escanearse en busca de ataques a la cadena de suministro y transferirse físicamente a un registro de artefactos interno. Los tokenizadores a menudo intentan descargar archivos de configuración en tiempo de ejecución: estas llamadas deben interceptarse y redirigirse a archivos locales.
2. El Motor de Inferencia: No puede depender de endpoints gestionados. Desplegamos servidores de inferencia locales optimizados como vLLM o Text Generation Inference (TGI) configurados estrictamente para ejecución offline. Estos se ejecutan en clústeres de GPU bare-metal dedicados dentro del firewall corporativo.
3. El Almacén de Vectores Local (Vector Store): Para las implementaciones RAG, las bases de datos vectoriales como Qdrant o Milvus deben desplegarse localmente. Despojamos a estos contenedores de cualquier telemetría predeterminada o configuraciones analíticas de "llamada a casa" antes del despliegue.
4. Telemetría Air-Gapped: La observabilidad no se puede subcontratar a Datadog o New Relic. Desplegamos pilas internas de Prometheus y Grafana para monitorear la utilización de GPU, la latencia de generación de tokens y los picos de memoria.
El Modelo Mental "Submarino" para la IA Offline
Al evaluar la infraestructura offline, piense en su aplicación de IA como un submarino. Una vez desplegada, es completamente autónoma. No puede pedir asistencia externa, parchearse a sí misma ni descargar nuevos mapas sobre la marcha.
Este marco obliga a los equipos de ingeniería y seguridad a alinearse. Si el sistema necesita una actualización (ya sea un nuevo peso de modelo Llama 3 o un parche de seguridad para el servidor de inferencia), requiere "atracar".
En un entorno empresarial, atracar significa utilizar diodos de datos seguros o hosts de salto DMZ fuertemente controlados. Las actualizaciones se tratan como paquetes de artefactos inmutables. Son sometidas a análisis estático, escaneo de malware y firma de artefactos antes de cruzar la brecha de aire (air gap).
Si su equipo asume que simplemente puede ejecutar un comando de gestor de paquetes para instalar una dependencia faltante durante el despliegue en producción, su arquitectura fallará.
Si se encuentra en esta etapa, aquí es donde una llamada de alcance con nosotros generalmente ahorra de 3 a 4 meses de tiempo de ingeniería desperdiciado.
Arquitectura del Mundo Real: Asegurando un Banco Regional
Recientemente diseñamos un sistema de IA completamente offline para una importante institución financiera. El mandato fue intransigente: procesar documentos internos de cumplimiento altamente confidenciales con cero llamadas de red externas.
El cliente había intentado previamente una construcción interna. Se estancó porque los desarrolladores no pudieron resolver los conflictos de dependencias sin acceso a internet, lo que provocó graves retrasos en el proyecto y presupuestos excedidos.
Desplegamos instancias localizadas de modelos optimizados y ajustados a instrucciones (instruction-tuned) que se ejecutan en clústeres de GPU internos fuertemente restringidos. Las tuberías de embedding y los sistemas de recuperación de vectores se incluyeron en contenedores y se les despojó de todos los mecanismos de sondeo de red externos.
Debido a los estrictos requisitos de residencia de datos, sometimos toda la infraestructura a nuestros exhaustivos protocolos de vapt penetration testing antes del lanzamiento. Validamos que ninguna inyección de prompts pudiera forzar al modelo a ejecutar solicitudes de red o extraer datos. Puede revisar las restricciones arquitectónicas exactas y los resultados de rendimiento en nuestro estudio de caso de implementación de banco regional.
Provisión de Hardware y Economía de Construir vs. Comprar
Para los CTOs y Vicepresidentes de Ingeniería, la decisión de implementar IA offline es en última instancia un cálculo económico. La compra de software de infraestructura de IA empresarial a menudo introduce vendor lock-in y formatos propietarios opacos.
Construirlo internamente requiere contratar ingenieros especializados en MLOps que comprendan el aprovisionamiento de GPU bare-metal. El dimensionamiento del hardware es el primer cuello de botella. No se puede escalar automáticamente (auto-scale) un rack de servidores air-gapped para satisfacer una demanda repentina.
La planificación de capacidad debe tener en cuenta el pico de demanda de generación de tokens. Calculamos los requisitos exactos de VRAM en función del máximo de usuarios concurrentes, el tamaño de la ventana de contexto y los niveles de cuantización (p. ej., AWQ o GPTQ) antes de ordenar un solo servidor.
Implementamos protocolos de procesamiento por lotes continuo (continuous batching) para maximizar la utilización del hardware sin depender de la elasticidad de la nube. Sus ingenieros afirmarán que pueden gestionar esta infraestructura. La realidad es que mantener tuberías de ML offline aleja a sus mejores desarrolladores de la construcción de productos financieros principales.
Mantenimiento del Sistema Air-Gapped a lo Largo de 18 Meses
El despliegue del modelo es solo el 20% del costo del ciclo de vida. El verdadero desafío de ingeniería es mantenerlo 18 meses después. Los entornos air-gapped inevitablemente sufren de deriva de dependencias (dependency drift).
Cuando se publica un CVE crítico para su base de datos vectorial, no puede simplemente ejecutar un script de parche automatizado a través de internet. Su arquitectura debe tener en cuenta la promoción estricta de artefactos offline.
Implementamos tuberías automatizadas que extraen las actualizaciones necesarias de los registros públicos a una DMZ orientada a internet. Allí, se escanean, se empaquetan como imágenes de contenedores firmadas que cumplen con OCI, y se mueven a través del límite seguro mediante medios físicos o soluciones estrictas de dominio cruzado.
Esto garantiza que su infraestructura offline permanezca parcheada y segura sin comprometer la brecha de aire. Requiere una disciplina rigurosa, pero es la única forma de operar IA en un entorno regulado.
Asegure su Infraestructura Financiera de IA
Construir una infraestructura de IA offline requiere una alineación profunda entre seguridad, cumplimiento e ingeniería de sistemas. No permita que su equipo interno trate una red air-gapped como una VPC estándar de la nube. Los riesgos para los datos de sus clientes son demasiado altos.
Si está evaluando partners de IA en los EAU o Pakistán, reserve una llamada de alcance de 30 minutos con Seven Labs: https://calendly.com/seven-labs-intro