
Cómo Delimitamos Proyectos de IA Que No Explotan en Producción
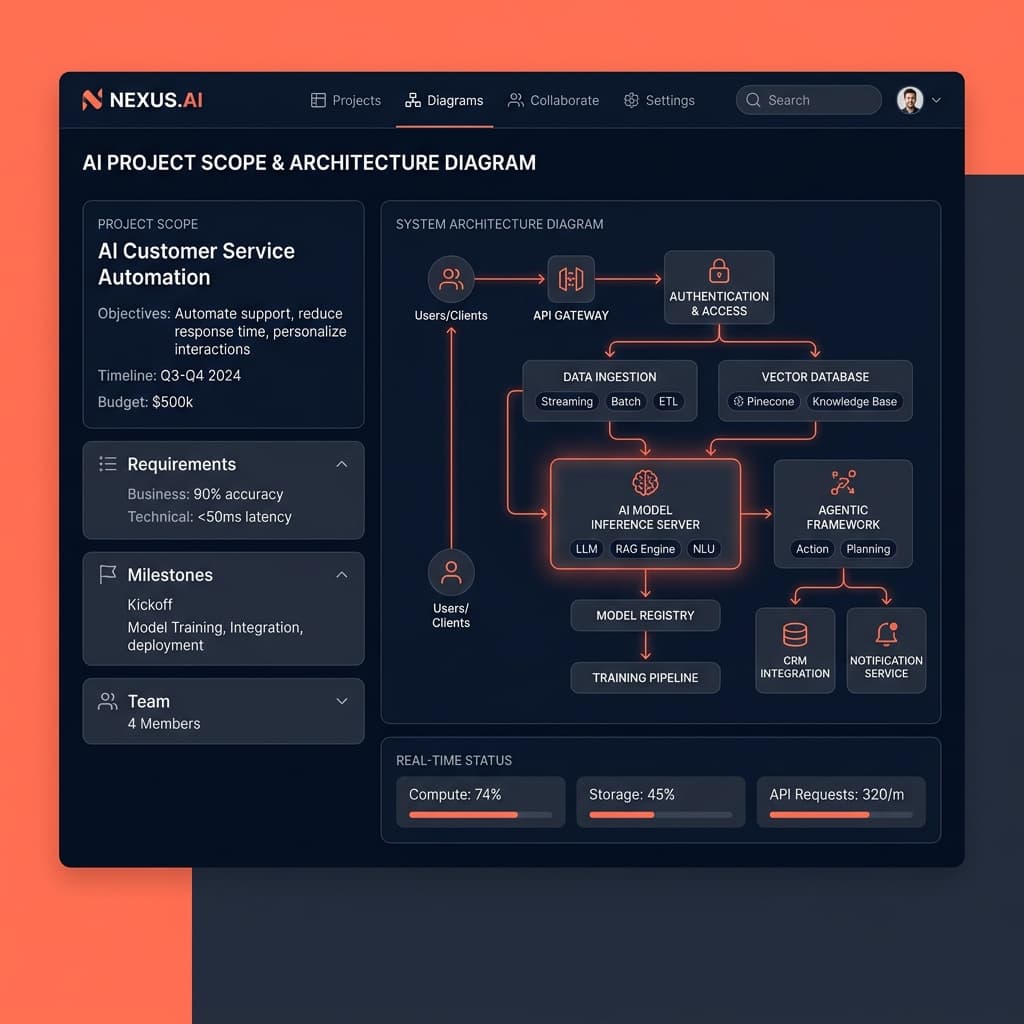
La mayoría de las iniciativas de IA empresarial fracasan porque los equipos de ingeniería tratan a los grandes modelos de lenguaje (LLMs) como APIs REST deterministas. Al definir el alcance (scoping) de proyectos de IA, no tener en cuenta las salidas probabilísticas y los casos extremos (edge cases) garantiza un colapso en producción exactamente cuando el volumen de usuarios escala.
Si su equipo interno piensa que puede envolver un endpoint de OpenAI en un shell de FastAPI y llamarlo un sistema empresarial, ya se dirige hacia un desastre.
La Trampa de "Podemos Construir Esto Internamente"
Los CTOs escuchan constantemente el mismo discurso de sus equipos de ingeniería. "Solo necesitamos una clave API, LangChain y una base de datos vectorial. Podemos lanzar esto en un sprint".
Suena simple. Construir el prototipo toma tres días. La demostración se ve impecable para el equipo ejecutivo.
Pero una demostración no es un sistema. Lo que sus ingenieros están proponiendo en realidad es asumir una carga de mantenimiento masiva y abierta que no están equipados para manejar.
La ingeniería de software estándar se basa en un estado determinista. Se pasa una entrada, se obtiene una salida predecible. La IA introduce probabilidad en la lógica central de su aplicación.
Sus desarrolladores web y sus ingenieros backend no son expertos en MLOps. No saben cómo manejar fallas de recuperación silenciosas, la degradación de la ventana de contexto o las inevitables regresiones del límite de tokens que ocurren bajo carga.
El costo de oportunidad de asignar a su equipo principal de producto la tarea de construir una infraestructura de IA a medida es masivo. Quema la velocidad del sprint en un problema que ya ha sido resuelto por firmas de ingeniería especializadas.
Dieciocho meses después, su equipo interno está empantanado manteniendo wrappers personalizados, luchando contra el vendor lock-in y reescribiendo la lógica central cada vez que un proveedor de modelos desaprueba (deprecates) una API. Pierde tiempo de comercialización y sus costos de mantenimiento se disparan.
Delimitar Proyectos de IA: Pasar de Demostraciones al Determinismo
La parte más difícil de delimitar proyectos de IA es definir qué sucede cuando el modelo inevitablemente falla.
El scoping de software estándar pregunta: "¿Qué debería hacer el sistema?". El scoping de IA empresarial debe preguntar: "¿Cómo se degrada elegantemente el sistema cuando el LLM alucina, pierde contexto o encuentra entradas fuera de distribución?".
Los casos extremos imprevistos y las fallas de escalamiento debido a un mal scoping paralizarán su implementación. Los equipos naturalmente optimizan para el "camino feliz" (happy path) donde la consulta del usuario está perfectamente estructurada y la recuperación vectorial es impecable.
En producción, los usuarios no siguen el camino feliz. Escriben consultas ambiguas y mal formateadas. Pegan PDFs de 50,000 tokens que abruman la ventana de contexto y hacen que el modelo descarte instrucciones silenciosamente.
Los usuarios intentan la inyección de prompts. Desencadenan límites de tasa (rate limits). Solicitan datos que no tienen autorización para ver.
Si el alcance inicial de su proyecto no define explícitamente tuberías de evaluación, heurísticas de respaldo (fallback) y guardarraíles automatizados, su sistema explotará en producción.
Un alcance de grado de producción dicta exactamente cómo se capturan y reintentan las salidas JSON mal formadas del LLM antes de que rompan sus aplicaciones descendentes (downstream). Define SLA de latencia y las estrategias de almacenamiento en caché requeridas para cumplirlos.
El Marco: Arquitectura Sobre Ingeniería de Prompts
Cuando delimitamos compromisos en Seven Labs, forzamos al liderazgo técnico a cambiar su modelo mental. Deje de pensar en el prompt. Empiece a pensar en la tubería (pipeline).
El marco que utilizamos es la regla 85/15 de la arquitectura de IA. Exactamente el 85% de su esfuerzo de ingeniería debe gastarse en la orquestación de datos, la gestión del estado, la lógica de recuperación y la evaluación.
Solo el 15% pertenece a la interacción con el LLM en sí.
Una arquitectura robusta requiere almacenamiento en caché semántico para reducir la latencia y los costos de API. Requiere la reescritura de consultas: un paso intermedio donde la entrada sin procesar del usuario se normaliza antes de que llegue a su base de datos vectorial.
Exige una capa de infraestructura dedicada para la redacción de PII. Requiere arquitecturas de búsqueda híbrida que combinen embeddings de vectores densos con búsqueda de palabras clave BM25, porque la similitud vectorial por sí sola es terrible para encontrar números de serie exactos o acrónimos.
Ninguno de estos desafíos de infraestructura se resuelve escribiendo un mejor prompt.
Si su documento de alcance pasa más páginas debatiendo la selección del modelo entre GPT-4 y Claude que definiendo su infraestructura de datos, está optimizando la variable equivocada.
Si su equipo de ingeniería interno está luchando para pasar una función de IA del prototipo a producción, aquí es donde una llamada de alcance con nosotros generalmente ahorra de 3 a 4 meses de tiempo de ingeniería desperdiciado.
Sobrevivir a las Restricciones que Priorizan la Seguridad (Security-First)
Las fallas de alcance se vuelven catastróficas cuando opera en industrias reguladas como la banca, fintech o la atención médica. No se puede modernizar la seguridad en una tubería de IA a posteriori.
Cuando construimos un sistema automatizado de análisis de vulnerabilidades para una importante institución financiera (lea nuestro estudio de caso del banco VAPT), el alcance fue dictado por completo por restricciones rígidas de confianza cero (zero-trust).
No podíamos simplemente enviar registros (logs) de pruebas de penetración crudos y datos de topología de red a una API pública en la nube. El alcance requería un despliegue de modelo local y aislado (air-gapped) en infraestructura soberana.
Diseñamos una tubería utilizando modelos de pesos abiertos implementados en bare metal. Implementamos el aislamiento de inquilinos a nivel de solicitud y un estricto Control de Acceso Basado en Roles (RBAC) en la capa de embedding.
Esto garantizó que la contaminación cruzada entre diferentes conjuntos de datos departamentales fuera criptográficamente imposible.
Si el alcance inicial hubiera asumido el acceso a la API en la nube, toda la arquitectura habría sido rechazada por el equipo de InfoSec del banco durante la primera revisión de implementación.
Anticipar los requisitos de cumplimiento, residencia de datos y SOC 2 en el Día 1 es la única forma de enviar IA empresarial en los mercados del Golfo y globales. Delimitar la seguridad significa mapear los límites exactos del flujo de datos antes de escribir una sola línea de código.
Definiendo la Carga de Mantenimiento del "Día 2"
Enviar el proyecto a producción es el Día 1. El Día 2 es donde los costos ocultos de un mal scoping destruyen su presupuesto operativo.
Los LLMs se actualizan continuamente entre bastidores. Un sistema que funciona sin problemas hoy se degradará silenciosamente cuando la API subyacente cambie su ajuste de alineación (alignment tuning) o filtros de seguridad.
El índice de su base de datos vectorial experimentará deriva (drift) a medida que evolucione su corpus de documentos subyacente. La calidad de su recuperación disminuirá lentamente y sus usuarios comenzarán a quejarse de que la IA se está volviendo "más tonta".
¿Quién en su equipo está monitoreando esto? ¿Quién ejecuta pruebas de regresión contra un conjunto de datos dorado (golden dataset) cada vez que se actualiza la versión de un modelo?
Cuando desplegamos AI platforms para nuestros clientes empresariales, incluimos en el alcance la tubería CI/CD para los modelos en sí. Esto es LLMOps, y es un requisito estricto para producción.
Desplegamos telemetría que rastrea la latencia de tokens, las tasas de alucinación y el costo por consulta en tiempo real. Construimos bucles de evaluación automatizados utilizando marcos "LLM-as-a-judge" para detectar regresiones antes de que los usuarios las vean.
Sin esta infraestructura en su alcance, no tiene un producto de IA. Tiene un pasivo no monitoreado esperando a romperse.
Deje de Construir Juguetes
Delimitar un proyecto de IA es un ejercicio fundamental en la mitigación de riesgos. O bien está diseñando para escalar, seguridad y determinismo desde el principio, o estará pagando por la reescritura total seis meses después.
No permita que su equipo de ingeniería construya un juguete cuando su empresa necesita un sistema seguro y de alta disponibilidad.
Si está evaluando partners de IA en los EAU o Pakistán para construir infraestructura de grado de producción, reserve una llamada de alcance de 30 minutos con Seven Labs: https://calendly.com/seven-labs-intro