
Waarom uw Gulf Enterprise AI Agency u een Chatbot verkoopt (En wat u eigenlijk nodig heeft)
De meeste bedrijven in de VAE en Saoedi-Arabië verbranden enorme engineeringbudgetten aan proof-of-concept AI-tools die nooit productie bereiken. U heeft geen nieuwe OpenAI-wrapper nodig; u heeft veerkrachtige, compliant systemen nodig.
Bij het evalueren van een enterprise AI-bureau in de Golf, moet de focus verschuiven van de onderliggende foundation models naar strikte security, architectuur en implementatierealisaties. De regio beweegt snel en heeft het budget voor grootschalige implementaties.
Enterprise-leiders raken echter steeds meer gefrustreerd door leveranciers die te veel beloven en te weinig leveren. Als uw organisatie artificial intelligence wil integreren, heeft u een bedrijf nodig dat robuuste softwarearchitectuur bouwt, geen presentatiedecks.
De Chatbot Illusie en Waarom Deze Faalt
De markt wordt momenteel overspoeld met leveranciers die basisscripts maskeren als complexe engineering. De meeste bureaus verkopen u een chatbot en noemen het AI.
Ze verbinden een standaard LLM API aan uw openbare website of interne wiki, schrijven een basis system prompt en beschouwen het project als voltooid. Deze benadering faalt onmiddellijk binnen een echte enterprise-omgeving.
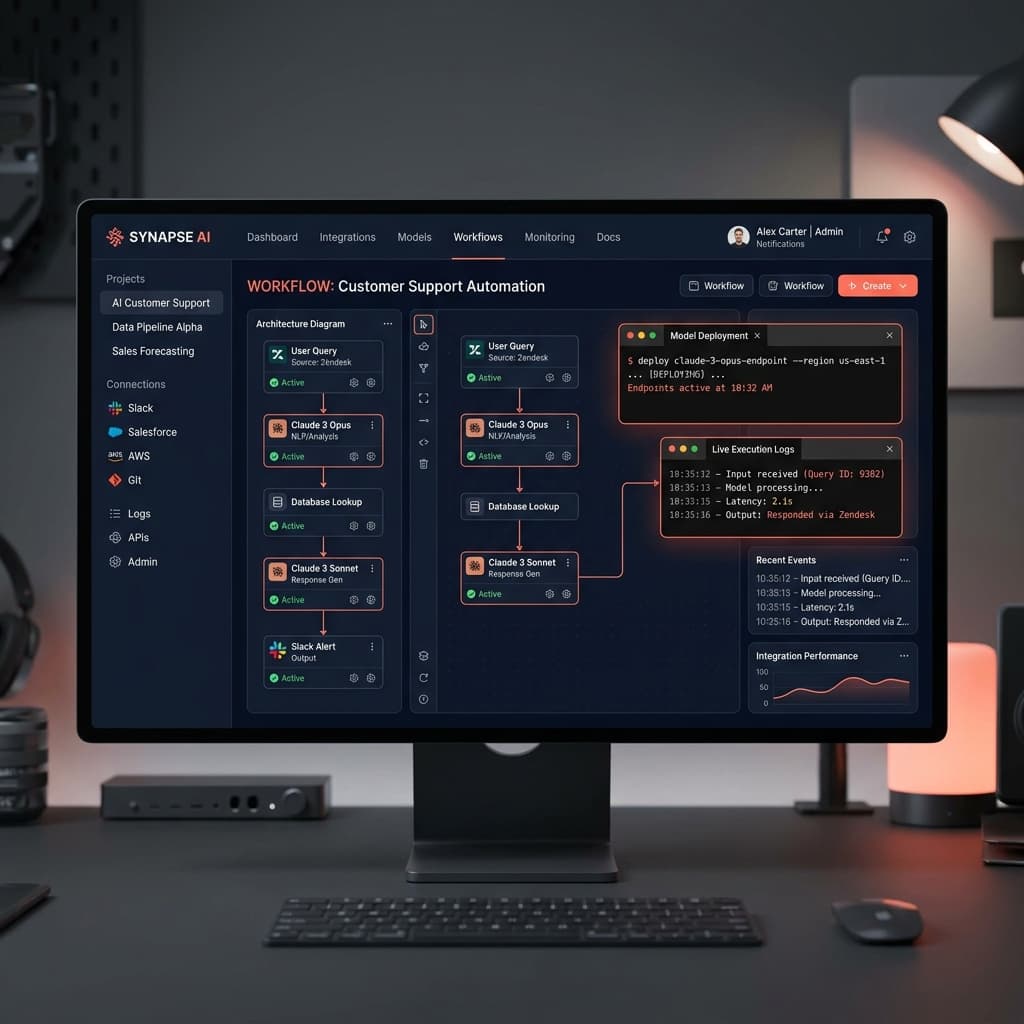
Een basis Retrieval-Augmented Generation (RAG) script kan niet omgaan met permissies op documentniveau. In een bedrijfshiërarchie, als uw CEO een vraag stelt, zou deze toegang moeten hebben tot andere data dan een stagiair die hetzelfde systeem bevraagt.
Wanneer u een basischatbot inzet zonder strikte Role-Based Access Control (RBAC), introduceert u massale datalek risico's. Uw engineeringteam zal de komende zes maanden besteden aan het patchen van prompt injection kwetsbaarheden in plaats van het bouwen van core productfeatures.
Een Gulf Enterprise AI Agency Evalueren: Speelgoed vs. Infrastructuur
We gebruiken een eenvoudig mentaal model bij Seven Labs: koopt u speelgoed, of bouwt u infrastructuur?
Speelgoed werkt perfect in gecontroleerde, geïsoleerde demo's. Ze zien er geweldig uit in directiekamer presentaties. Infrastructuur behandelt edge cases, API rate limits, ongestructureerde data pipelines en strikte compliance mandaten.
Een architectuur op productieniveau vereist rigoureuze evaluatie pipelines. Als u de system prompt aanpast of het embedding model updatet, heeft u geautomatiseerde regressietesten nodig om te bewijzen dat de nauwkeurigheid niet is verslechterd over duizenden testgevallen.
U heeft ook vector database synchronisatie nodig die in realtime updatet wanneer onderliggende brondocumenten veranderen. Verouderde data in een vector database leidt direct tot bedrijfsbrede hallucinaties.
Dit is het exacte verschil tussen een bureau dat API calls schrijft en een engineeringbedrijf dat veerkrachtige AI platforms levert. Wij bouwen systemen met observability ingebakken vanaf dag één.
Wanneer er een anomalie optreedt, moet u precies weten waarom het model een specifiek antwoord gaf. U moet het uitvoeringspad kunnen traceren en exact de document chunk die het raadpleegde kunnen debuggen.
Als u in deze fase zit, is dit waar een scoping call met ons doorgaans 3-4 maanden aan verspilde engineeringtijd bespaart.
Security, Data Residency en De Air-Gap Realiteit
Bedrijven in de Golf, met name in de financiële en overheidssector, opereren onder strikte regelgevende kaders. Datasoevereiniteit is niet optioneel.
U kunt geen ongeredigeerde financiële dossiers of PII naar een openbaar API-endpoint sturen dat wordt gehost in een Amerikaans datacenter. Uw compliance en juridische teams zullen de implementatie terecht op dag één blokkeren.
We hebben onlangs een air-gapped oplossing ontwikkeld voor een regionale bank. Tijdens de architectuurfase brachten we hun absolute zero-trust vereisten in kaart.
We implementeerden gefinetunede, open-source modellen direct binnen hun lokale Virtual Private Cloud (VPC). Er heeft nooit gevoelige data hun perimeter verlaten. Alle document chunking, embedding en inference gebeurde lokaal.
We hebben niet alleen het model geïmplementeerd; we hebben de veiligheid ervan bewezen. Ons team voerde rigoureuze red-teaming uit tegen de infrastructuur. U kunt de methodologie bekijken in onze VAPT bank penetration testing case study.
Een AI-systeem dat niet door een rigoureuze penetratietest komt, is een massale bedrijfsverplichting, geen technologisch bezit.
Engineering voor Arabische en Complexe Lokale Contexten
De meeste kant-en-klare AI-tools zijn sterk bevooroordeeld naar de Engelse syntaxis en schone digitale tekst. Ze lopen vast wanneer ze worden geïntroduceerd in de operationele realiteit van bedrijven in de Golf.
Uw systemen bevatten waarschijnlijk een mix van Arabische en Engelse documenten, gescande PDF's van de overheid met watermerken en complexe financiële tabellen. Een standaard OCR-pipeline kan deze niet correct parseren.
Als het model de tabel tijdens de ingestiefase niet correct kan lezen, zal geen enkele hoeveelheid prompt engineering de output repareren. Garbage in, garbage out blijft de fundamentele wet van AI.
Wij bouwen op maat gemaakte ingestie pipelines die tweetalige documentatie correct afhandelen. We maken gebruik van geavanceerde chunking strategieën die semantische grenzen in zowel het Arabisch als het Engels respecteren.
Dit zorgt ervoor dat de vector search de precieze context ophaalt die nodig is, in plaats van gefragmenteerde, betekenisloze zinnen uit een slecht geparseerde PDF te halen.
De Vendor Lock-In Realiteit met SaaS AI Wrappers
Veel bedrijven trappen in de val van de aankoop van zware SaaS-platforms die fungeren als wrappers rond standaard LLM's.
Deze platforms beloven een naadloze integratie, maar worden al snel een enorme belemmering. U zit vast aan hun specifieke ecosysteem, hun prijsmodellen en hun update cycli.
Als er volgende maand een open-source model uitkomt dat 50% goedkoper is en 20% nauwkeuriger voor uw specifieke use case, kunt u niet zomaar migreren. U bent gebonden aan de roadmap van uw leverancier.
Wij bouwen AI architecturen op basis van modulaire, open-source principes. We ontkoppelen de opslaglaag (zoals Postgres met pgvector) van de orchestratielaag en de inference engine.
Deze modulariteit geeft u de vrijheid om onderliggende modellen te verwisselen naarmate de technologie evolueert. U bent eigenaar van de architectuur en u wordt nooit gegijzeld door API-wijzigingen van een enkele leverancier.
De Build vs. Buy Val voor In-House Teams
Uw interne engineers zullen zeggen dat ze dit kunnen bouwen. Ze zullen erop wijzen dat de open-source bibliotheken toegankelijk zijn en de documentatie duidelijk is.
Dit is het verkeerde gesprek om te voeren. Het prototypen van een AI-applicatie in een weekend is triviaal. Het onderhouden ervan in productie over een tijdlijn van 18 maanden is een compleet andere technische discipline.
API's worden snel afgeschreven. Het afhandelen van context windows wordt exponentieel complex. De nauwkeurigheid van semantische zoekopdrachten verslechtert naarmate uw database groeit van honderden documenten naar miljoenen.
Het inhuren van toegewijde AI-engineers in Dubai om deze infrastructuur te onderhouden is ongelooflijk duur. Bovendien is de talentpool van engineers die daadwerkelijk AI-systemen op productieniveau hebben gelanceerd uitzonderlijk klein.
Wanneer uw core engineeringteam dit op zich neemt, daalt hun sprint velocity voor daadwerkelijke kernproduct features naar nul. U ruilt in feite product iteratie in voor AI-onderhoud.
Samenwerken met een engineeringgerichte studio neemt deze last volledig weg. Het stelt uw in-house team in staat zich volledig te concentreren op proprietary business logic terwijl wij de drift van de AI-infrastructuur beheren.
De Verborgen Kosten van Slechte AI Architectuur
Wanneer u een oppervlakkige oplossing koopt, betaalt u er twee keer voor. De eerste factuur van het bureau is nog maar het begin.
De verborgen kosten komen aan het licht wanneer u probeert op te schalen. Niet-geoptimaliseerde vector search queries zullen uw database verstikken. Niet-gecachete API calls zorgen ervoor dat uw maandelijkse inference kosten uit de hand lopen.
U betaalt ook in latency. Een slecht geoptimaliseerde AI-pipeline kan tien seconden nodig hebben om een query te retourneren. In een productieomgeving met echte gebruikers vernietigt hoge latency de adoptiecijfers.
Het repareren van deze architecturale fouten vereist het uitrukken van de fundering. U eindigt met het betalen van een echt engineeringbedrijf om het hele systeem vanaf nul te herschrijven. We maken gebruik van semantische caching en edge deployments om ervoor te zorgen dat uw systemen in milliseconden reageren, niet in seconden.
De Drie Vragen die u uw Volgende AI-Partner Moet Stellen
Stop met leveranciers te vragen welke foundation models ze gebruiken. De modellen zelf zijn goederen die elke drie maanden veranderen. Begin te vragen hoe ze het systeem rond het model ontwerpen.
Ten eerste, vraag hoe ze document permissie mapping afhandelen tijdens vector search. Als ze aarzelen of een workaround voorstellen, hebben ze nog nooit enterprise RAG-systemen gebouwd.
Ten tweede, vraag naar hun exacte methodologie voor het testen van prompt injection en geautomatiseerde data exfiltratie. Als hun antwoord is "we gebruiken een sterke system prompt", loop dan onmiddellijk weg.
Ten derde, eis een duidelijk pad naar lokale implementatie. Zelfs als u vandaag begint op een managed cloud infrastructuur, kunnen wijzigingen in de regelgeving in de VAE u dwingen om morgen on-premise te gaan. Uw architectuur moet die ommezwaai kunnen ondersteunen zonder een totale herschrijving.
De aanvankelijke hype-cyclus is voorbij. Bedrijven realiseren zich dat het integreren van AI rigoureuze software engineering, strikte security protocollen en diepgaande architectonische kennis vereist. Neem geen genoegen met nieuw speelgoed.
Als u AI-partners evalueert in de VAE of Pakistan, boek dan een scoping call van 30 minuten met Seven Labs: https://calendly.com/seven-labs-intro