
Hoe we de scope bepalen van AI-projecten die niet in productie ontploffen
De meeste enterprise AI-initiatieven mislukken omdat engineeringteams large language models behandelen als deterministische REST API's. Bij het bepalen van de scope van AI-projecten, is het niet incalculeren van probabilistische outputs en edge cases een garantie voor een meltdown in productie precies wanneer het gebruikersvolume schaalt.
Als uw interne team denkt dat ze een OpenAI endpoint kunnen verpakken in een FastAPI shell en het een enterprise systeem kunnen noemen, loopt u al op een ramp af.
De "We Kunnen Dit In-House Bouwen" Val
CTO's horen constant dezelfde pitch van hun engineeringteams. "We hebben alleen een API key, LangChain en een vector database nodig. We kunnen dit in één sprint lanceren."
Het klinkt eenvoudig. Het bouwen van het prototype duurt drie dagen. De demo ziet er vlekkeloos uit voor het managementteam.
Maar een demo is geen systeem. Wat uw engineers daadwerkelijk voorstellen is het op zich nemen van een massale, open-ended onderhoudslast die ze niet kunnen afhandelen.
Standaard software engineering vertrouwt op een deterministische state. U geeft een input, u krijgt een voorspelbare output. AI introduceert waarschijnlijkheid in uw core applicatielogica.
Uw webontwikkelaars en backend engineers zijn geen MLOps experts. Ze weten niet hoe ze om moeten gaan met stille retrieval fouten, context window degradatie of de onvermijdelijke token limiet regressies die optreden onder belasting.
De opportunity cost van het belasten van uw core productteam met het bouwen van op maat gemaakte AI-infrastructuur is enorm. U verbrandt sprint velocity aan een probleem dat al is opgelost door gespecialiseerde engineeringbedrijven.
Achttien maanden later is uw in-house team vastgelopen in het onderhouden van custom wrappers, het bestrijden van vendor lock-in en het herschrijven van core logica telkens wanneer een modelprovider een API afschrijft. U verliest time-to-market en uw onderhoudskosten rijzen de pan uit.
De Scope van AI-projecten Bepalen: Van Demo's naar Determinisme
Het moeilijkste deel van het afbakenen van AI-projecten is bepalen wat er gebeurt wanneer het model onvermijdelijk faalt.
Standaard software scoping vraagt: "Wat moet het systeem doen?" Enterprise AI scoping moet vragen: "Hoe degradeert het systeem op een sierlijke manier (graceful degradation) wanneer de LLM hallucineert, context verliest of out-of-distribution inputs tegenkomt?"
Onvoorziene edge cases en schaalproblemen als gevolg van slechte scoping zullen uw implementatie verlammen. Teams optimaliseren van nature voor het "happy path" waar de gebruikersquery perfect gestructureerd is en de vector retrieval vlekkeloos is.
In productie volgen gebruikers het happy path niet. Ze schrijven dubbelzinnige, slecht geformatteerde query's. Ze plakken PDF's van 50.000 tokens die de context window overspoelen en ervoor zorgen dat het model stilletjes instructies laat vallen.
Gebruikers proberen prompt injection. Ze triggeren rate limits. Ze vragen om data die ze niet mogen zien.
Als uw initiële projectscope evaluatie pipelines, fallback heuristieken en geautomatiseerde guardrails niet expliciet definieert, zal uw systeem ontploffen in productie.
Een scope op productieniveau dicteert precies hoe misvormde JSON-outputs van de LLM worden opgevangen en opnieuw geprobeerd voordat ze uw downstream applicaties breken. Het definieert latency SLA's en de caching strategieën die nodig zijn om hieraan te voldoen.
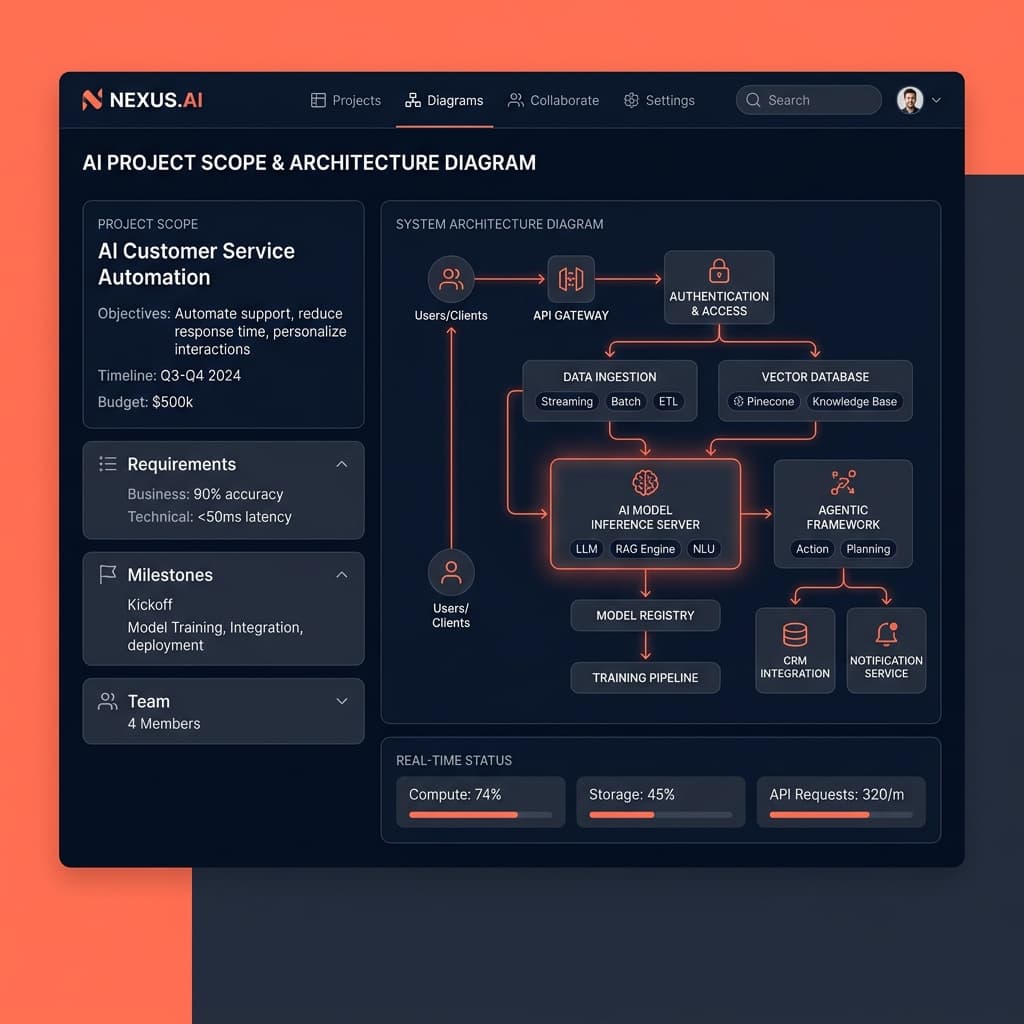
Het Raamwerk: Architectuur Boven Prompt Engineering
Wanneer we de scope bepalen van opdrachten bij Seven Labs, dwingen we technisch leiderschap om hun mentale model te veranderen. Stop met nadenken over de prompt. Begin na te denken over de pipeline.
Het raamwerk dat we gebruiken is de 85/15-regel van AI-architectuur. Precies 85% van uw technische inspanning moet worden besteed aan data orchestratie, state management, retrieval logica en evaluatie.
Slechts 15% behoort toe aan de LLM-interactie zelf.
Een robuuste architectuur vereist semantic caching om latency en API-kosten te verlagen. Het vereist query herschrijven - een tussenstap waarbij de ruwe input van de gebruiker wordt genormaliseerd voordat het ooit uw vector database raakt.
Het vereist een toegewijde infrastructuurlaag voor PII-redactie. Het vereist hybride zoekarchitecturen die dichte vector embeddings combineren met BM25 trefwoord zoeken, omdat vector gelijkenis alleen waardeloos is in het vinden van exacte serienummers of acroniemen.
Geen van deze infrastructuuruitdagingen wordt opgelost door een betere prompt te schrijven.
Als uw scoping document meer pagina's besteedt aan het debatteren over modelselectie tussen GPT-4 en Claude dan aan het definiëren van uw data infrastructuur, optimaliseert u de verkeerde variabele.
Als uw interne engineeringteam moeite heeft om een AI-feature van prototype naar productie te verplaatsen, is dit waar een scoping call met ons doorgaans 3-4 maanden aan verspilde engineeringtijd bespaart.
Overleven met Security-First Beperkingen
Scoping fouten worden catastrofaal wanneer u opereert in sterk gereguleerde sectoren zoals het bankwezen, fintech of de gezondheidszorg. U kunt beveiliging niet achteraf in een AI-pipeline inbouwen.
Toen we een geautomatiseerd analyse systeem voor kwetsbaarheden bouwden voor een grote financiële instelling (lees onze VAPT bank case study), werd de scope volledig gedicteerd door rigide, zero-trust beperkingen.
We konden niet zomaar ruwe penetratietest logs en netwerktopologie data naar een public cloud API sturen. De scope vereiste een lokale, air-gapped implementatie van het model op soevereine infrastructuur.
We ontwierpen een pipeline met behulp van open-weight modellen die werden ingezet op bare metal. We implementeerden tenant-isolatie op verzoeksniveau en strikte Role-Based Access Control (RBAC) op de embedding-laag.
Dit zorgde ervoor dat kruisbesmetting tussen datasets van verschillende afdelingen cryptografisch onmogelijk was.
Als de initiële scope was uitgegaan van cloud API-toegang, zou de volledige architectuur door het InfoSec-team van de bank zijn afgewezen tijdens de eerste implementatiebeoordeling.
Het anticiperen op compliance, data residency en SOC 2 eisen op Dag 1 is de enige manier om enterprise AI te lanceren in de Golf en wereldwijde enterprise-markten. Scoping voor security betekent het in kaart brengen van de exacte grenzen van datastromen voordat er ook maar één regel code wordt geschreven.
De "Dag 2" Onderhoudslast Definiëren
Het lanceren van het project naar productie is Dag 1. Dag 2 is waar de verborgen kosten van slechte scoping uw operationele budget vernietigen.
LLM's worden achter de schermen continu geüpdatet. Een systeem dat vandaag feilloos werkt, zal stilletjes degraderen wanneer de onderliggende API zijn alignment tuning of veiligheidsfilters wijzigt.
Uw vector database index zal te maken krijgen met drift naarmate uw onderliggende document corpus evolueert. De kwaliteit van uw retrieval zal langzaam dalen, en uw gebruikers zullen beginnen te klagen dat de AI "dommer" wordt.
Wie in uw team houdt dit in de gaten? Wie voert regressietests uit tegen een golden dataset telkens wanneer een modelversie wordt verhoogd?
Wanneer we AI platforms implementeren voor onze enterprise klanten, bepalen we de scope van de CI/CD pipeline voor de modellen zelf. Dit is LLMOps, en het is een harde vereiste voor productie.
We implementeren telemetrie die token latency, hallucinatie percentages en kosten-per-query in realtime bijhoudt. We bouwen geautomatiseerde evaluatie loops met behulp van LLM-as-a-judge frameworks om regressies op te vangen voordat gebruikers ze zien.
Zonder deze infrastructuur in uw scope heeft u geen AI-product. U heeft een ongecontroleerde verplichting die wacht om te breken.
Stop met het Bouwen van Speelgoed
De scope van een AI-project bepalen is een fundamentele oefening in risicobeperking. U bouwt vanaf het begin voor schaal, beveiliging en determinisme, of u betaalt zes maanden later voor de volledige herschrijving.
Laat uw engineeringteam geen speelgoed bouwen wanneer uw onderneming een zeer beschikbaar, veilig systeem nodig heeft.
Als u AI-partners in de VAE of Pakistan evalueert om infrastructuur op productieniveau te bouwen, boek dan een scoping call van 30 minuten met Seven Labs: https://calendly.com/seven-labs-intro