
AI Deployment in Air-Gapped Financial Networks: A Practical Architecture Guide
Financial engineering teams face a strict binary: modernize compliance and fraud detection with Large Language Models, or maintain data residency by keeping networks entirely isolated. You cannot simply pipe sensitive customer PII to an external API without triggering immediate compliance breach risks. Central bank mandates in the Gulf and global SOC 2 requirements explicitly forbid this kind of data leakage.
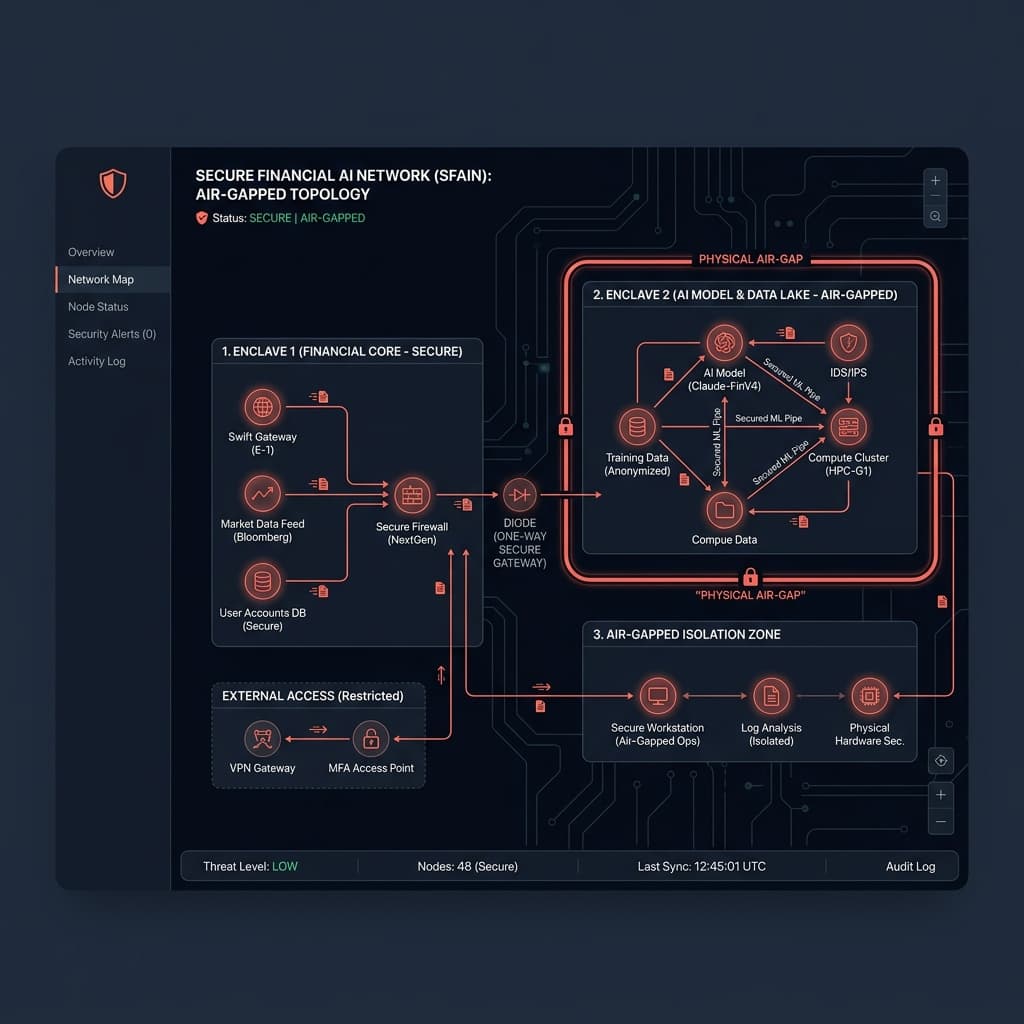
To solve this, infrastructure teams must master AI deployment in air-gapped networks. This requires severing all external dependencies and architecting systems that operate with zero external network connectivity. It is a fundamental shift from cloud-native engineering.
The Compliance Breach Risk of "Good Intentions"
Your internal developers will tell you they can build an offline Retrieval-Augmented Generation (RAG) pipeline in a weekend. They are answering the wrong question. Getting an open-source model to run locally on a laptop is trivial.
Hardening that model for production inside a restricted financial network is an entirely different engineering discipline. The primary pain point is data residency. When a user queries a model with transaction histories or KYC documents, that data cannot leave the local network under any circumstances.
The failure mode here is severe. A single developer accidentally logging sensitive data to a cloud-hosted observability tool-or embedding a hidden call to OpenAI for debugging-can trigger a massive compliance breach risk. Fines in regulated markets operate on a percentage of global revenue, not flat fees.
This creates the "Shadow AI" problem. Engineers, frustrated by strict network restrictions, find hidden workarounds to access cloud models. The only defense is providing a production-grade, fully offline alternative that is just as fast and reliable as external APIs.
Designing AI Deployment in Air-Gapped Networks
Standard cloud-native AI architectures assume infinite bandwidth and constant connectivity to package registries. Designing AI deployment in air-gapped networks requires inverting this paradigm. Your system cannot call out to Hugging Face, NPM, or external telemetry services.
We break offline infrastructure down into four isolated tiers:
1. The Offline Model Registry: Model weights (safetensors) and tokenizers must be downloaded externally, scanned for supply chain attacks, and physically transferred to an internal artifact registry. Tokenizers often attempt to download configuration files at runtime-these calls must be trapped and redirected to local files.
2. The Inference Engine: You cannot rely on managed endpoints. We deploy optimized local inference servers like vLLM or Text Generation Inference (TGI) configured strictly for offline execution. These run on dedicated bare-metal GPU clusters within the corporate firewall.
3. The Local Vector Store: For RAG implementations, vector databases like Qdrant or Milvus must be deployed locally. We strip these containers of any default telemetry or "phone home" analytics configurations before deployment.
4. Air-Gapped Telemetry: Observability cannot be outsourced to Datadog or New Relic. We deploy internal Prometheus and Grafana stacks to monitor GPU utilization, token generation latency, and memory spikes.
The "Submarine" Mental Model for Offline AI
When evaluating offline infrastructure, think of your AI application as a submarine. Once deployed, it is completely autonomous. It cannot call for outside assistance, patch itself, or download new maps on the fly.
This framework forces engineering and security teams to align. If the system needs an update-whether it is a new Llama 3 model weight or a security patch for the inference server-it requires "docking."
In an enterprise setting, docking means utilizing secure data diodes or tightly controlled DMZ jump hosts. Updates are treated as immutable artifact bundles. They are subjected to static analysis, malware scanning, and artifact signing before crossing the air gap.
If your team assumes they can just run a package manager command to install a missing dependency during production deployment, your architecture will fail.
If you're at this stage, this is where a scoping call with us usually saves 3-4 months of wasted engineering time.
Real-World Architecture: Securing a Regional Bank
We recently architected a fully offline AI system for a major financial institution. The mandate was uncompromising: process highly sensitive internal compliance documents with zero external network calls.
The client had previously attempted an internal build. It stalled because developers could not resolve dependency conflicts without internet access, leading to severe project delays and blown budgets.
We deployed localized instances of optimized, instruction-tuned models running on heavily restricted internal GPU clusters. The embedding pipelines and vector retrieval systems were containerized and stripped of all external network polling mechanisms.
Because of the strict data residency requirements, we subjected the entire infrastructure to our comprehensive vapt penetration testing protocols before going live. We validated that no prompt injection could force the model to execute network requests or exfiltrate data. You can review the exact architectural constraints and performance outcomes in our regional bank deployment case study.
Hardware Provisioning and Build vs. Buy Economics
For CTOs and VPs of Engineering, the decision to deploy offline AI is ultimately an economic calculation. Buying enterprise AI infrastructure software often introduces vendor lock-in and opaque proprietary formats.
Building it internally requires hiring specialized MLOps engineers who understand bare-metal GPU provisioning. Hardware sizing is the first bottleneck. You cannot auto-scale an air-gapped server rack to meet sudden demand.
Capacity planning must account for peak token generation demand. We calculate exact VRAM requirements based on maximum concurrent users, context window sizes, and quantization levels (e.g., AWQ or GPTQ) before a single server is ordered.
We implement continuous batching protocols to maximize hardware utilization without relying on cloud elasticity. Your engineers will claim they can manage this infrastructure. The reality is that maintaining offline ML pipelines pulls your best developers away from building core financial products.
Maintaining the Air-Gapped System Over 18 Months
Deploying the model is only 20% of the lifecycle cost. The true engineering challenge is maintaining it 18 months later. Air-gapped environments inevitably suffer from dependency drift.
When a critical CVE is published for your vector database, you cannot simply run an automated patch script over the internet. Your architecture must account for strict offline artifact promotion.
We implement automated pipelines that pull necessary updates from public registries into an internet-facing DMZ. There, they are scanned, packaged as signed OCI-compliant container images, and moved across the secure boundary via physical media or strict cross-domain solutions.
This guarantees that your offline infrastructure remains patched and secure without compromising the air gap. It requires rigorous discipline, but it is the only way to operate AI in a regulated environment.
Secure Your Financial AI Infrastructure
Building offline AI infrastructure requires deep alignment between security, compliance, and systems engineering. Do not let your internal team treat an air-gapped network like a standard cloud VPC. The risks to your customer data are too high.
If you're evaluating AI partners in the UAE or Pakistan, book a 30-minute scoping call with Seven Labs: https://calendly.com/seven-labs-intro