
Déploiement de l'IA dans les réseaux financiers isolés : Un guide d'architecture pratique
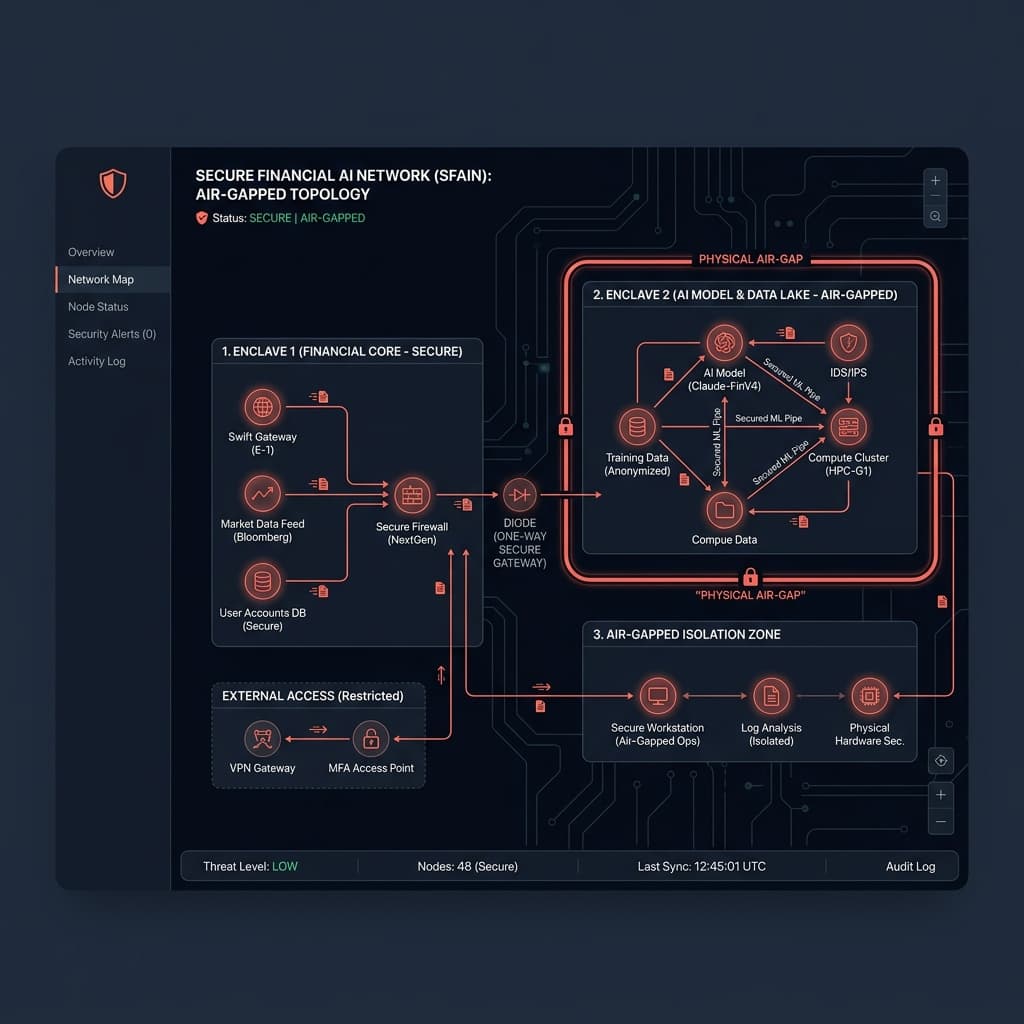
Les équipes d'ingénierie financière sont confrontées à une alternative stricte : moderniser la conformité et la détection des fraudes avec de grands modèles de langage (LLMs), ou maintenir la résidence des données en gardant les réseaux entièrement isolés. Vous ne pouvez pas simplement transférer des données personnelles (PII) sensibles de clients vers une API externe sans déclencher immédiatement des risques de violation de la conformité. Les mandats des banques centrales du Golfe et les exigences globales SOC 2 interdisent explicitement ce type de fuite de données.
Pour résoudre ce problème, les équipes d'infrastructure doivent maîtriser le déploiement de l'IA dans des réseaux isolés (air-gapped). Cela nécessite de rompre toutes les dépendances externes et de concevoir des systèmes qui fonctionnent avec une connectivité réseau externe nulle. C'est un changement fondamental par rapport à l'ingénierie cloud-native.
Le risque de violation de la conformité lié aux "bonnes intentions"
Vos développeurs internes vous diront qu'ils peuvent construire un pipeline de Retrieval-Augmented Generation (RAG) hors ligne en un week-end. Ils ne répondent pas à la bonne question. Faire tourner un modèle open-source localement sur un ordinateur portable est trivial.
Renforcer (harden) ce modèle pour la production à l'intérieur d'un réseau financier restreint est une discipline d'ingénierie entièrement différente. Le principal point de douleur est la résidence des données. Lorsqu'un utilisateur interroge un modèle avec des historiques de transactions ou des documents KYC, ces données ne peuvent en aucun cas quitter le réseau local.
Le mode d'échec ici est sévère. Un seul développeur enregistrant accidentellement des données sensibles dans un outil d'observabilité hébergé dans le cloud - ou intégrant un appel caché à OpenAI pour le débogage - peut déclencher un risque massif de violation de la conformité. Sur les marchés réglementés, les amendes fonctionnent en pourcentage des revenus mondiaux, et non en frais fixes.
Cela crée le problème du "Shadow AI". Les ingénieurs, frustrés par les restrictions strictes du réseau, trouvent des solutions de contournement cachées pour accéder aux modèles cloud. La seule défense est de fournir une alternative hors ligne de niveau production qui soit tout aussi rapide et fiable que les API externes.
Concevoir le déploiement de l'IA dans des réseaux isolés
Les architectures d'IA cloud-natives standard supposent une bande passante infinie et une connectivité constante aux registres de paquets. Concevoir un déploiement d'IA dans des réseaux isolés (air-gapped) nécessite d'inverser ce paradigme. Votre système ne peut pas faire appel à Hugging Face, NPM ou à des services de télémétrie externes.
Nous divisons l'infrastructure hors ligne en quatre niveaux isolés :
1. Le registre de modèles hors ligne : Les poids des modèles (safetensors) et les tokenizers doivent être téléchargés en externe, scannés pour détecter les attaques sur la chaîne d'approvisionnement, et transférés physiquement vers un registre d'artefacts interne. Les tokenizers tentent souvent de télécharger des fichiers de configuration à l'exécution - ces appels doivent être interceptés et redirigés vers des fichiers locaux.
2. Le moteur d'inférence : Vous ne pouvez pas vous fier aux points de terminaison gérés. Nous déployons des serveurs d'inférence locaux optimisés comme vLLM ou Text Generation Inference (TGI), configurés strictement pour une exécution hors ligne. Ceux-ci s'exécutent sur des clusters GPU bare-metal dédiés au sein du pare-feu de l'entreprise.
3. Le stockage vectoriel local : Pour les implémentations RAG, les bases de données vectorielles comme Qdrant ou Milvus doivent être déployées localement. Nous dépouillons ces conteneurs de toute télémétrie par défaut ou configuration d'analyse "phone home" avant le déploiement.
4. Télémétrie isolée : L'observabilité ne peut pas être externalisée à Datadog ou New Relic. Nous déployons des piles Prometheus et Grafana internes pour surveiller l'utilisation du GPU, la latence de génération des tokens et les pics de mémoire.
Le modèle mental du "sous-marin" pour l'IA hors ligne
Lors de l'évaluation de l'infrastructure hors ligne, pensez à votre application d'IA comme à un sous-marin. Une fois déployée, elle est complètement autonome. Elle ne peut pas appeler d'assistance extérieure, se patcher elle-même, ou télécharger de nouvelles cartes à la volée.
Ce cadre oblige les équipes d'ingénierie et de sécurité à s'aligner. Si le système a besoin d'une mise à jour - qu'il s'agisse des poids d'un nouveau modèle Llama 3 ou d'un patch de sécurité pour le serveur d'inférence - il nécessite un "amarrage" (docking).
Dans un environnement d'entreprise, l'amarrage signifie l'utilisation de diodes de données sécurisées ou de serveurs de rebond (jump hosts) DMZ étroitement contrôlés. Les mises à jour sont traitées comme des bundles d'artefacts immuables. Elles sont soumises à une analyse statique, à une analyse anti-malware et à une signature d'artefact avant de franchir l'air gap (isolation physique).
Si votre équipe suppose qu'elle peut simplement exécuter une commande de gestionnaire de paquets pour installer une dépendance manquante pendant le déploiement en production, votre architecture échouera.
Si vous en êtes à ce stade, c'est là qu'un appel de cadrage avec nous vous fera généralement économiser 3 à 4 mois de temps d'ingénierie gaspillé.
Architecture du monde réel : Sécuriser une banque régionale
Nous avons récemment conçu un système d'IA entièrement hors ligne pour une grande institution financière. Le mandat était sans compromis : traiter des documents de conformité internes hautement sensibles avec zéro appel réseau externe.
Le client avait précédemment tenté une construction interne. Elle s'était enlisée parce que les développeurs ne pouvaient pas résoudre les conflits de dépendances sans accès à Internet, ce qui a entraîné d'importants retards dans le projet et des dépassements de budget.
Nous avons déployé des instances localisées de modèles optimisés, ajustés sur des instructions, exécutées sur des clusters GPU internes fortement restreints. Les pipelines d'embedding et les systèmes de récupération vectorielle ont été conteneurisés et dépouillés de tous les mécanismes d'interrogation du réseau externe.
En raison des exigences strictes de résidence des données, nous avons soumis l'ensemble de l'infrastructure à nos protocoles complets de vapt penetration testing avant la mise en production. Nous avons validé qu'aucune injection de prompt ne pouvait forcer le modèle à exécuter des requêtes réseau ou à exfiltrer des données. Vous pouvez examiner les contraintes architecturales exactes et les résultats de performance dans notre étude de cas sur le déploiement d'une banque régionale.
Provisionnement matériel et économie du Build vs. Buy
Pour les CTO et les vice-présidents de l'ingénierie, la décision de déployer une IA hors ligne est en fin de compte un calcul économique. L'achat de logiciels d'infrastructure d'IA d'entreprise introduit souvent un enfermement propriétaire (vendor lock-in) et des formats propriétaires opaques.
La construire en interne nécessite d'embaucher des ingénieurs MLOps spécialisés qui comprennent le provisionnement GPU bare-metal. Le dimensionnement du matériel est le premier goulot d'étranglement. Vous ne pouvez pas mettre à l'échelle automatiquement un rack de serveurs isolé pour répondre à une demande soudaine.
La planification de la capacité doit tenir compte des pics de demande de génération de tokens. Nous calculons les exigences exactes en VRAM en fonction du nombre maximal d'utilisateurs simultanés, de la taille des fenêtres de contexte et des niveaux de quantification (par exemple, AWQ ou GPTQ) avant même la commande d'un seul serveur.
Nous mettons en œuvre des protocoles de traitement par lots continu (continuous batching) pour maximiser l'utilisation du matériel sans recourir à l'élasticité du cloud. Vos ingénieurs prétendront qu'ils peuvent gérer cette infrastructure. La réalité est que la maintenance des pipelines ML hors ligne éloigne vos meilleurs développeurs de la création de produits financiers de base.
Maintenir le système isolé sur 18 mois
Déployer le modèle ne représente que 20 % du coût du cycle de vie. Le véritable défi d'ingénierie est de le maintenir 18 mois plus tard. Les environnements isolés souffrent inévitablement de dérive des dépendances.
Lorsqu'une CVE critique est publiée pour votre base de données vectorielle, vous ne pouvez pas simplement exécuter un script de correctif automatisé via Internet. Votre architecture doit tenir compte d'une promotion stricte d'artefacts hors ligne.
Nous mettons en œuvre des pipelines automatisés qui extraient les mises à jour nécessaires des registres publics vers une DMZ connectée à Internet. Là, elles sont scannées, empaquetées en tant qu'images de conteneurs conformes à OCI et signées, puis déplacées à travers la frontière sécurisée via des supports physiques ou des solutions strictes inter-domaines.
Cela garantit que votre infrastructure hors ligne reste corrigée et sécurisée sans compromettre l'isolation physique. Cela demande une discipline rigoureuse, mais c'est la seule façon d'exploiter l'IA dans un environnement réglementé.
Sécurisez votre infrastructure d'IA financière
Construire une infrastructure d'IA hors ligne nécessite un alignement profond entre la sécurité, la conformité et l'ingénierie des systèmes. Ne laissez pas votre équipe interne traiter un réseau isolé comme un VPC cloud standard. Les risques pour les données de vos clients sont trop élevés.
Si vous évaluez des partenaires IA aux Émirats Arabes Unis ou au Pakistan, réservez un appel de cadrage de 30 minutes avec Seven Labs : https://calendly.com/seven-labs-intro