
Pourquoi votre agence d'IA d'entreprise du Golfe vous vend un Chatbot (et ce dont vous avez réellement besoin)
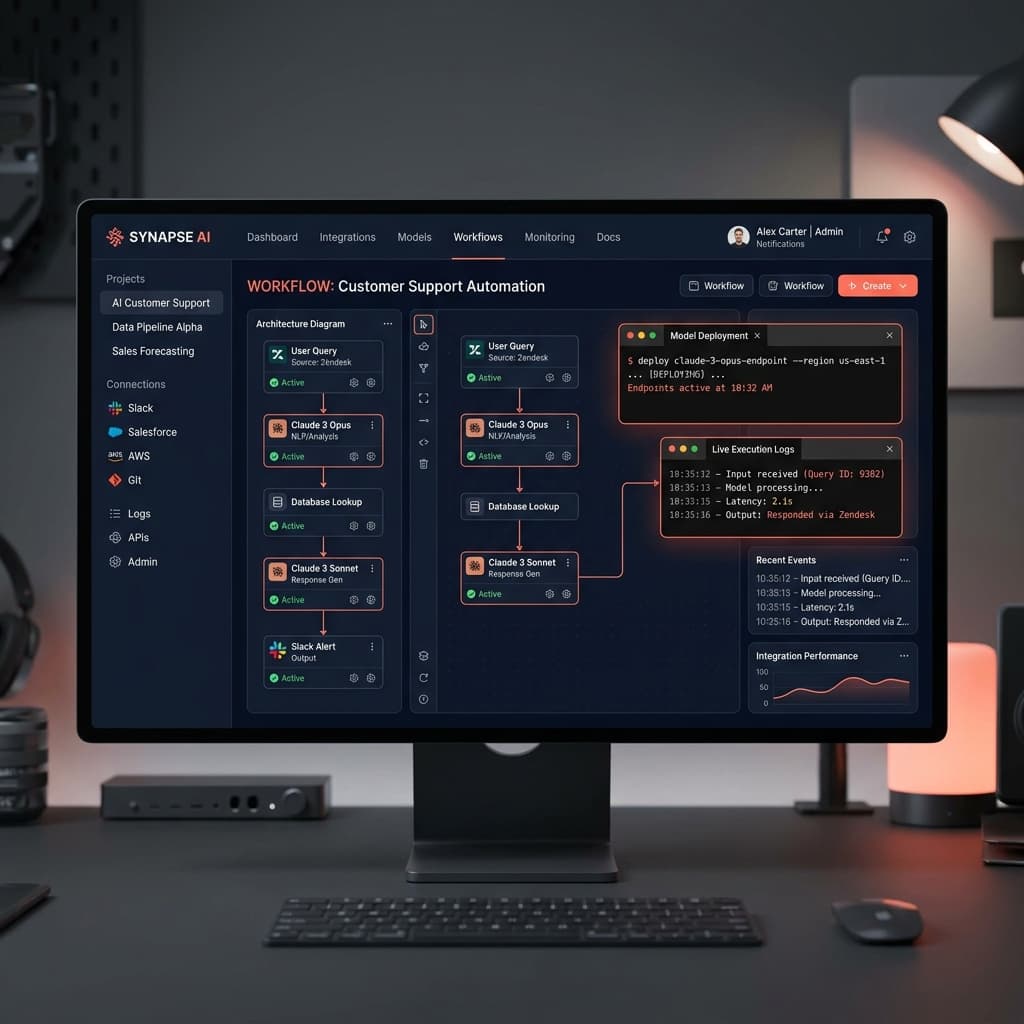
La plupart des entreprises aux Émirats Arabes Unis et en Arabie Saoudite brûlent des budgets d'ingénierie massifs dans des preuves de concept d'outils d'IA qui n'atteignent jamais la production. Vous n'avez pas besoin d'un énième wrapper OpenAI ; vous avez besoin de systèmes résilients et conformes.
Lors de l'évaluation d'une agence d'IA d'entreprise dans le Golfe, l'accent doit passer des modèles de base sous-jacents aux réalités strictes de la sécurité, de l'architecture et du déploiement. La région évolue rapidement et dispose du budget nécessaire pour des implémentations à grande échelle.
Cependant, les dirigeants d'entreprise sont de plus en plus frustrés par des fournisseurs qui promettent trop et livrent trop peu. Si votre organisation cherche à intégrer l'intelligence artificielle, vous avez besoin d'une entreprise qui construit une architecture logicielle robuste, et non des présentations PowerPoint.
L'illusion du Chatbot et pourquoi elle échoue
Le marché est actuellement inondé de fournisseurs qui font passer des scripts de base pour de l'ingénierie complexe. La plupart des agences vous vendent un chatbot et l'appellent IA.
Ils connectent une API LLM standard à votre site web public ou à votre wiki interne, écrivent un prompt système de base et considèrent le projet comme terminé. Cette approche échoue immédiatement au sein d'un véritable environnement d'entreprise.
Un script de base de Retrieval-Augmented Generation (RAG) ne peut pas gérer les permissions au niveau des documents. Dans une hiérarchie d'entreprise, si votre PDG pose une question, il devrait accéder à des données différentes de celles d'un stagiaire interrogeant le même système.
Lorsque vous déployez un chatbot de base sans contrôle d'accès strict basé sur les rôles (RBAC), vous introduisez des risques massifs de fuite de données. Votre équipe d'ingénierie passera les six prochains mois à corriger des vulnérabilités d'injection de prompt au lieu de construire les fonctionnalités de base du produit.
Évaluer une agence d'IA d'entreprise du Golfe : Jouets vs Infrastructure
Nous utilisons un modèle mental simple chez Seven Labs : achetez-vous un jouet ou construisez-vous une infrastructure ?
Les jouets fonctionnent parfaitement dans des démonstrations contrôlées et isolées. Ils présentent bien dans les salles de conseil. L'infrastructure gère les cas particuliers, les limites de requêtes API, les pipelines de données non structurées et les mandats stricts de conformité.
Une architecture de niveau production nécessite des pipelines d'évaluation rigoureux. Si vous modifiez le prompt système ou mettez à jour le modèle d'embedding, vous avez besoin de tests de régression automatisés pour prouver que la précision ne s'est pas dégradée sur des milliers de cas de test.
Vous avez également besoin d'une synchronisation de la base de données vectorielle qui se met à jour en temps réel lorsque les documents sources sous-jacents changent. Des données obsolètes dans une base de données vectorielle conduisent directement à des hallucinations d'entreprise.
C'est la différence exacte entre une agence qui écrit des appels API et une société d'ingénierie qui livre des plateformes d'IA résilientes. Nous construisons des systèmes avec l'observabilité intégrée dès le premier jour.
Lorsqu'une anomalie se produit, vous devez savoir exactement pourquoi le modèle a donné une réponse spécifique. Vous devez être capable de retracer le chemin d'exécution et de déboguer le morceau (chunk) exact de document auquel il a fait référence.
Si vous en êtes à ce stade, c'est là qu'un appel de cadrage avec nous vous fera généralement économiser 3 à 4 mois de temps d'ingénierie gaspillé.
Sécurité, résidence des données et la réalité des systèmes isolés
Les entreprises du Golfe, en particulier dans les secteurs de la finance et du gouvernement, opèrent sous des cadres réglementaires stricts. La souveraineté des données n'est pas optionnelle.
Vous ne pouvez pas envoyer de dossiers financiers non caviardés ou de PII (données personnelles) vers un point de terminaison d'API public hébergé dans un centre de données américain. Vos équipes de conformité et juridiques bloqueront à juste titre le déploiement dès le premier jour.
Nous avons récemment conçu une solution isolée (air-gapped) pour une banque régionale. Au cours de la phase d'architecture, nous avons cartographié leurs exigences absolues de zero-trust.
Nous avons déployé des modèles open source affinés directement au sein de leur Virtual Private Cloud (VPC) local. Aucune donnée sensible n'a jamais quitté leur périmètre. Le découpage des documents, les embeddings et l'inférence ont eu lieu localement.
Nous n'avons pas seulement déployé le modèle ; nous avons prouvé sa sécurité. Notre équipe a exécuté un red-teaming rigoureux contre l'infrastructure. Vous pouvez examiner la méthodologie dans notre étude de cas sur les tests de pénétration pour une banque.
Un système d'IA qui ne peut pas passer un test de pénétration rigoureux est un passif massif pour l'entreprise, pas un atout technologique.
Ingénierie pour l'arabe et les contextes locaux complexes
La plupart des outils d'IA prêts à l'emploi sont fortement biaisés en faveur de la syntaxe anglaise et du texte numérique propre. Ils s'effondrent lorsqu'ils sont confrontés à la réalité opérationnelle des entreprises du Golfe.
Vos systèmes contiennent probablement un mélange de documents en arabe et en anglais, des PDF gouvernementaux numérisés avec des filigranes et des tableaux financiers complexes. Un pipeline OCR standard ne peut pas les analyser correctement.
Si le modèle ne peut pas lire le tableau correctement pendant la phase d'ingestion, aucune quantité de prompt engineering ne corrigera la sortie. "Garbage in, garbage out" reste la loi fondamentale de l'IA.
Nous construisons des pipelines d'ingestion personnalisés qui gèrent correctement la documentation bilingue. Nous utilisons des stratégies de chunking avancées qui respectent les limites sémantiques en arabe et en anglais.
Cela garantit que la recherche vectorielle récupère le contexte précis requis, plutôt que d'extraire des phrases fragmentées et dénuées de sens d'un PDF mal analysé.
La réalité de l'enfermement propriétaire avec les wrappers d'IA SaaS
De nombreuses entreprises tombent dans le piège d'acheter de lourdes plateformes SaaS qui agissent comme des wrappers autour de LLM standards.
Ces plateformes promettent une intégration transparente mais deviennent rapidement un passif massif. Vous êtes verrouillé dans leur écosystème spécifique, leurs modèles de tarification et leurs cycles de mise à jour.
Si un modèle open source sort le mois prochain qui est 50 % moins cher et 20 % plus précis pour votre cas d'usage spécifique, vous ne pouvez pas migrer facilement. Vous êtes lié à la feuille de route de votre fournisseur.
Nous construisons des architectures d'IA basées sur des principes modulaires et open source. Nous découplons la couche de stockage (comme Postgres avec pgvector) de la couche d'orchestration et du moteur d'inférence.
Cette modularité vous donne la liberté de remplacer les modèles sous-jacents au fur et à mesure que la technologie évolue. Vous possédez l'architecture, et vous n'êtes jamais pris en otage par les changements d'API d'un seul fournisseur.
Le piège du Build vs. Buy pour les équipes internes
Vos ingénieurs internes diront qu'ils peuvent construire cela. Ils souligneront que les bibliothèques open source sont accessibles et la documentation claire.
Ce n'est pas la bonne conversation à avoir. Prototyper une application d'IA en un week-end est trivial. La maintenir en production sur une période de 18 mois est une discipline d'ingénierie complètement différente.
Les API sont dépréciées rapidement. La gestion des fenêtres de contexte devient exponentiellement complexe. La précision de la recherche sémantique se dégrade à mesure que votre base de données passe de centaines de documents à des millions.
L'embauche d'ingénieurs IA dédiés à Dubaï pour maintenir cette infrastructure est incroyablement coûteuse. De plus, le vivier de talents d'ingénieurs qui ont réellement mis en production des systèmes d'IA est exceptionnellement restreint.
Lorsque votre équipe d'ingénierie principale s'en charge, leur vélocité de sprint pour les fonctionnalités du produit principal tombe à zéro. Vous échangez effectivement l'itération du produit contre la maintenance de l'IA.
S'associer à un studio axé sur l'ingénierie élimine entièrement ce fardeau. Cela permet à votre équipe interne de se concentrer entièrement sur la logique métier propriétaire pendant que nous gérons la dérive de l'infrastructure IA.
Les coûts cachés d'une mauvaise architecture IA
Lorsque vous achetez une solution superficielle, vous la payez deux fois. La facture initiale de l'agence n'est que le début.
Les coûts cachés apparaissent lorsque vous tentez de passer à l'échelle. Des requêtes de recherche vectorielle non optimisées ralentiront votre base de données. Des appels API non mis en cache feront grimper en flèche vos coûts d'inférence mensuels.
Vous paierez également en latence. Un pipeline d'IA mal optimisé peut prendre dix secondes pour renvoyer une requête. Dans un environnement de production face à de vrais utilisateurs, une latence élevée détruit les taux d'adoption.
La correction de ces défauts architecturaux nécessite d'arracher les fondations. Vous finissez par payer une véritable société d'ingénierie pour réécrire l'ensemble du système à partir de zéro. Nous utilisons la mise en cache sémantique et les déploiements en périphérie (edge) pour nous assurer que vos systèmes répondent en millisecondes, pas en secondes.
Les trois questions que vous devez poser à votre prochain partenaire IA
Arrêtez de demander aux fournisseurs quels modèles de base ils utilisent. Les modèles eux-mêmes sont des commodités qui changent tous les trois mois. Commencez à demander comment ils conçoivent l'architecture du système autour du modèle.
Tout d'abord, demandez comment ils gèrent la correspondance des permissions des documents pendant la recherche vectorielle. S'ils hésitent ou proposent une solution de contournement, ils n'ont jamais construit de systèmes RAG d'entreprise.
Deuxièmement, demandez leur méthodologie exacte pour tester l'injection de prompt et l'exfiltration de données automatisée. Si leur réponse est "nous utilisons un prompt système fort", partez immédiatement.
Troisièmement, exigez un chemin clair vers le déploiement local. Même si vous commencez sur une infrastructure cloud gérée aujourd'hui, les changements réglementaires aux Émirats Arabes Unis pourraient vous forcer à passer sur site (on-premise) demain. Votre architecture doit soutenir ce pivot sans une réécriture totale.
Le cycle initial d'engouement est terminé. Les entreprises réalisent que l'intégration de l'IA nécessite une ingénierie logicielle rigoureuse, des protocoles de sécurité stricts et de profondes connaissances architecturales. Ne vous contentez pas d'un autre jouet.
Si vous évaluez des partenaires IA aux Émirats Arabes Unis ou au Pakistan, réservez un appel de cadrage de 30 minutes avec Seven Labs : https://calendly.com/seven-labs-intro